Dự án chạy ngon lành với 1,000 records. Lên 100,000 — vẫn ổn. Đến 1 triệu records, endpoint /api/invoices bắt đầu mất 3-4 giây. Lên 5 triệu, timeout. Mở pgAdmin chạy EXPLAIN ANALYZE — thấy dòng chữ đáng sợ: Seq Scan on invoices (cost=0.00..185432.00 rows=5000000). Sequential scan toàn bộ 5 triệu records.
Thêm index đúng chỗ — query từ 3 giây xuống 2 millisecond. Không đổi một dòng code nào.
Index là thứ có impact lớn nhất đến performance mà ít tốn effort nhất. Nhưng thêm index bừa bãi cũng gây hại — mỗi index tốn disk space, chậm INSERT/UPDATE, và có thể khiến PostgreSQL chọn execution plan tệ hơn. Bài viết này chia sẻ strategy mình dùng để quyết định khi nào cần index, loại index nào, và cách verify index thực sự được dùng.
EXPLAIN ANALYZE — Bắt đầu từ đây, luôn luôn
Trước khi thêm bất kỳ index nào, phải hiểu query đang chạy ra sao. EXPLAIN ANALYZE là công cụ quan trọng nhất:
EXPLAIN ANALYZE
SELECT * FROM invoices
WHERE tenant_id = 1
AND status = 'Approved'
AND created_at >= '2025-01-01'
ORDER BY created_at DESC
LIMIT 20;
Output (chưa có index):
Sort (cost=28453.21..28453.26 rows=18 width=312) (actual time=1847.234..1847.238 rows=20 loops=1)
Sort Key: created_at DESC
Sort Method: top-N heapsort Memory: 35kB
-> Seq Scan on invoices (cost=0.00..28453.00 rows=18 width=312) (actual time=0.031..1845.127 rows=4523 loops=1)
Filter: ((tenant_id = 1) AND (status = 'Approved') AND (created_at >= '2025-01-01'))
Rows Removed by Filter: 4995477
Planning Time: 0.128 ms
Execution Time: 1847.315 ms
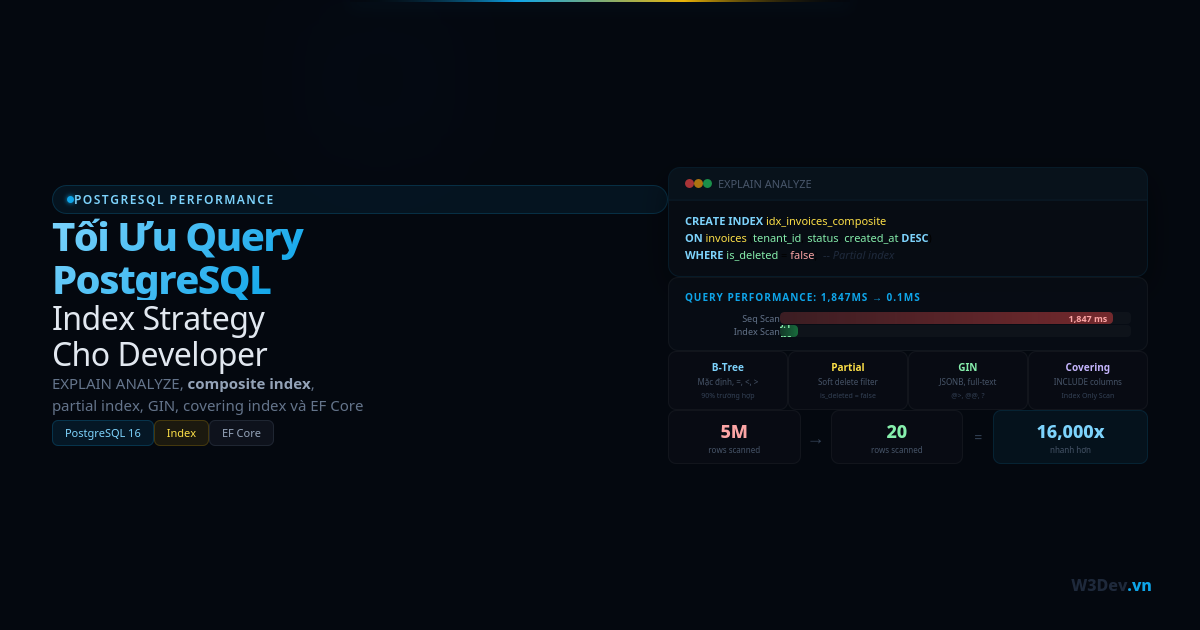
Đọc output này: PostgreSQL scan toàn bộ bảng (Seq Scan), đọc 5 triệu rows, filter bỏ 4,995,477 rows, giữ lại 4,523 rows, sort, rồi lấy 20 rows. Mất 1.8 giây chỉ để lấy 20 records.
Hai con số quan trọng nhất: actual time (thời gian thực tế) và Rows Removed by Filter (bao nhiêu rows đọc lên rồi bỏ). Nếu bỏ nhiều hơn giữ — cần index.
B-Tree Index — 90% trường hợp dùng cái này
B-Tree là default index type trong PostgreSQL. Tạo index không chỉ định type thì mặc định là B-Tree. Hiệu quả cho: equality (=), range (>, <, >=, <=, BETWEEN), sorting (ORDER BY), và IS NULL / IS NOT NULL.
Single column index
CREATE INDEX idx_invoices_tenant_id ON invoices (tenant_id);
Query WHERE tenant_id = 1 giờ dùng index thay vì scan toàn bộ bảng. Nhưng nếu query có nhiều conditions thì sao?
Composite index — Thứ tự columns quan trọng
CREATE INDEX idx_invoices_tenant_status_created
ON invoices (tenant_id, status, created_at DESC);
Composite index hoạt động theo nguyên tắc leftmost prefix — index trên (A, B, C) sử dụng được cho: query có A, query có A, B, query có A, B, C. Nhưng KHÔNG dùng được cho query chỉ có B hoặc C mà không có A.
Quy tắc sắp xếp columns trong composite index: equality columns trước (columns dùng với =), range columns sau (columns dùng với >, <, BETWEEN), sort column cuối cùng.
Ví dụ query ở trên: tenant_id = 1 (equality) → status = 'Approved' (equality) → created_at >= '2025-01-01' (range) → ORDER BY created_at DESC (sort). Nên index tối ưu là (tenant_id, status, created_at DESC).
Sau khi thêm index:
Limit (cost=0.56..18.23 rows=20 width=312) (actual time=0.048..0.089 rows=20 loops=1)
-> Index Scan using idx_invoices_tenant_status_created on invoices
Index Cond: ((tenant_id = 1) AND (status = 'Approved') AND (created_at >= '2025-01-01'))
Planning Time: 0.215 ms
Execution Time: 0.112 ms
Từ 1,847ms xuống 0.112ms — nhanh hơn 16,000 lần. PostgreSQL đi thẳng vào index, lấy đúng 20 rows cần thiết, không đọc row nào thừa.
Partial Index (Filtered Index) — Index chỉ những gì cần
Nếu 95% queries chỉ lấy records active (không bị xóa), tại sao index cả records đã xóa?
-- Index toàn bộ: 5 triệu records
CREATE INDEX idx_invoices_tenant ON invoices (tenant_id);
-- Partial index: chỉ records active (~4.75 triệu records)
CREATE INDEX idx_invoices_tenant_active
ON invoices (tenant_id)
WHERE is_deleted = false;
Partial index nhỏ hơn, nhanh hơn, ít tốn disk space hơn. PostgreSQL chỉ maintain index cho records thỏa điều kiện WHERE.
Nếu bạn dùng Soft Delete với Global Query Filter trong EF Core (mọi query đều có WHERE is_deleted = false), partial index là lựa chọn tốt nhất:
// EF Core configuration
entity.HasIndex(e => new { e.TenantId, e.Status, e.CreatedAt })
.HasFilter("\"is_deleted\" = false");
Partial index đặc biệt hiệu quả khi: tỷ lệ records thỏa điều kiện nhỏ (ví dụ chỉ 5% records có status = 'Pending'), có global filter áp dụng cho hầu hết queries (soft delete, tenant isolation), hoặc cần unique constraint chỉ cho records active.
Unique partial index — Unique chỉ trong scope
-- InvoiceNumber unique per tenant, chỉ cho records chưa xóa
CREATE UNIQUE INDEX idx_invoices_number_unique
ON invoices (tenant_id, invoice_number)
WHERE is_deleted = false;
Cho phép: tenant 1 có invoice INV-001 active và INV-001 đã xóa (soft delete rồi tạo lại). Ngăn: tenant 1 có hai invoice INV-001 cùng active.
GIN Index — Cho JSONB, Array, Full-text Search
B-Tree không hiệu quả cho JSONB queries hay full-text search. GIN (Generalized Inverted Index) được thiết kế cho những trường hợp này.
JSONB index
-- Nếu bạn lưu metadata dạng JSONB
-- {"category": "summer", "width": 205, "tags": ["premium", "eco"]}
-- GIN index cho toàn bộ JSONB column
CREATE INDEX idx_products_metadata_gin
ON products USING GIN (metadata);
-- Dùng cho queries:
SELECT * FROM products WHERE metadata @> '{"category": "summer"}';
SELECT * FROM products WHERE metadata ? 'tags';
GIN index cho JSONB hỗ trợ operators: @> (contains), ? (key exists), ?| (any key exists), ?& (all keys exist).
Nếu chỉ query một vài keys cụ thể, expression index trên key đó hiệu quả hơn GIN trên toàn bộ column:
-- Chỉ index một key cụ thể — nhỏ hơn, nhanh hơn
CREATE INDEX idx_products_category
ON products ((metadata->>'category'));
-- Dùng cho:
SELECT * FROM products WHERE metadata->>'category' = 'summer';
Full-text search index
-- Tạo column tsvector hoặc index expression
CREATE INDEX idx_products_search
ON products USING GIN (to_tsvector('english', name || ' ' || description));
-- Query
SELECT * FROM products
WHERE to_tsvector('english', name || ' ' || description)
@@ to_tsquery('english', 'michelin & summer');
GIN index build chậm hơn B-Tree nhiều và tốn disk space hơn. Đừng tạo GIN index "phòng xa" — chỉ tạo khi thực sự cần.
Expression Index — Index trên kết quả tính toán
Khi query dùng function hoặc expression, PostgreSQL không thể dùng index trên raw column:
-- Index trên email KHÔNG được dùng cho query này
SELECT * FROM customers WHERE LOWER(email) = 'john@example.com';
Vì LOWER(email) khác với email. Cần expression index:
CREATE INDEX idx_customers_email_lower
ON customers (LOWER(email));
-- Giờ query này dùng index
SELECT * FROM customers WHERE LOWER(email) = 'john@example.com';
Expression index hữu ích cho: case-insensitive search (LOWER(), UPPER()), date extraction (DATE(created_at), EXTRACT(YEAR FROM created_at)), JSONB key access ((metadata->>'category')), computed values.
Trong EF Core:
entity.HasIndex(e => e.Email)
.HasMethod("btree")
.HasDatabaseName("idx_customers_email_lower")
// EF Core không hỗ trợ expression index trực tiếp
// Dùng raw migration SQL
;
// Trong migration:
migrationBuilder.Sql(
"CREATE INDEX idx_customers_email_lower " +
"ON customers (LOWER(email))");
INCLUDE Columns — Index covering để tránh table lookup
Khi PostgreSQL tìm thấy row qua index, nó vẫn phải quay lại table (heap) để lấy các columns không có trong index. Gọi là "table lookup" hay "heap fetch." Nếu query chỉ cần vài columns, thêm chúng vào index bằng INCLUDE để tránh lookup:
-- Index thường: tìm qua index → quay lại table lấy data
CREATE INDEX idx_invoices_status ON invoices (tenant_id, status);
-- Covering index: tìm qua index → data đã có sẵn trong index
CREATE INDEX idx_invoices_status_covering
ON invoices (tenant_id, status)
INCLUDE (invoice_number, total_amount, created_at);
Khi query chỉ SELECT các columns có trong index + INCLUDE, PostgreSQL trả về kết quả chỉ từ index — không cần đọc table. Gọi là "Index Only Scan," nhanh hơn đáng kể khi table rất lớn.
-- Query này có thể dùng Index Only Scan
SELECT invoice_number, total_amount, created_at
FROM invoices
WHERE tenant_id = 1 AND status = 'Approved';
INCLUDE columns không dùng để filter hay sort — chỉ để "mang theo" data, tránh heap fetch. Đừng lạm dụng — thêm quá nhiều INCLUDE columns làm index phình to, INSERT/UPDATE chậm.
Khi nào KHÔNG nên thêm index
Index không phải silver bullet. Mỗi index có cost:
INSERT/UPDATE chậm hơn
Mỗi INSERT phải update tất cả indexes trên bảng đó. 1 index thêm ~10-20% overhead. 5 indexes có thể thêm 50-100%. Bảng có write-heavy workload (ví dụ bảng log, events) nên hạn chế index.
Disk space
Index tốn disk space riêng. Composite index trên bảng 5 triệu rows có thể tốn 200-500MB. Kiểm tra bằng:
SELECT
indexname,
pg_size_pretty(pg_relation_size(indexrelid)) AS index_size
FROM pg_stat_user_indexes
WHERE schemaname = 'public'
ORDER BY pg_relation_size(indexrelid) DESC;
Low cardinality columns
Column status chỉ có 5 giá trị (Draft, Pending, Approved, Rejected, Cancelled) — index single column trên status thường không hiệu quả. PostgreSQL quyết định scan toàn bộ bảng nhanh hơn dùng index khi index trả về quá nhiều rows (>5-10% tổng rows).
Nhưng status trong composite index (tenant_id, status) vẫn hiệu quả — vì tenant_id đã filter xuống ít rows, status lọc thêm trong tập nhỏ đó.
Bảng nhỏ
Bảng dưới vài ngàn rows — PostgreSQL scan toàn bộ nhanh hơn dùng index. Overhead đọc index rồi quay lại table có thể chậm hơn đọc thẳng table.
Tìm missing indexes — Cách systematic
pg_stat_user_tables — Bảng nào bị sequential scan nhiều?
SELECT
relname AS table_name,
seq_scan,
seq_tup_read,
idx_scan,
n_live_tup AS estimated_rows
FROM pg_stat_user_tables
WHERE seq_scan > 0
ORDER BY seq_tup_read DESC
LIMIT 10;
Bảng có seq_scan cao và seq_tup_read lớn mà idx_scan thấp — cần xem lại index strategy.
pg_stat_user_indexes — Index nào không được dùng?
SELECT
indexrelname AS index_name,
relname AS table_name,
idx_scan AS times_used,
pg_size_pretty(pg_relation_size(indexrelid)) AS index_size
FROM pg_stat_user_indexes
WHERE idx_scan = 0
AND indexrelname NOT LIKE '%_pkey'
AND indexrelname NOT LIKE '%_unique'
ORDER BY pg_relation_size(indexrelid) DESC;
Index có idx_scan = 0 (chưa bao giờ được dùng) mà tốn nhiều disk space — cân nhắc xóa. Nhưng check xem có phải index mới tạo hay index cho report chạy hàng tháng — counter reset khi restart PostgreSQL.
Slow query log
Bật pg_stat_statements hoặc set log_min_duration_statement để tìm slow queries:
-- PostgreSQL config (postgresql.conf)
-- log_min_duration_statement = 1000 -- log queries > 1 second
-- Với pg_stat_statements extension
SELECT
query,
calls,
mean_exec_time,
total_exec_time
FROM pg_stat_statements
ORDER BY mean_exec_time DESC
LIMIT 20;
Index strategy cho EF Core project
Index trong Entity Configuration
public class InvoiceConfiguration : IEntityTypeConfiguration<Invoice>
{
public void Configure(EntityTypeBuilder<Invoice> builder)
{
// Primary key — auto indexed
builder.HasKey(e => e.Id);
// Foreign key — EF Core tự tạo index cho FK
builder.HasOne(e => e.Customer)
.WithMany(c => c.Invoices)
.HasForeignKey(e => e.CustomerId);
// Composite index cho query pattern phổ biến
builder.HasIndex(e => new { e.TenantId, e.Status, e.CreatedAt })
.HasDatabaseName("idx_invoices_tenant_status_created")
.HasFilter("\"is_deleted\" = false");
// Unique partial index
builder.HasIndex(e => new { e.TenantId, e.InvoiceNumber })
.IsUnique()
.HasDatabaseName("idx_invoices_number_unique")
.HasFilter("\"is_deleted\" = false");
// Expression index — phải dùng raw SQL
}
}
Index cho pattern thường gặp
Soft delete + Multi-tenant (hầu hết query có cả hai filter):
builder.HasIndex(e => new { e.TenantId, e.Status, e.CreatedAt })
.HasFilter("\"is_deleted\" = false");
Foreign key lookup (navigation property, Include):
// EF Core tự tạo index cho FK, nhưng composite FK index phải tạo thủ công
builder.HasIndex(e => new { e.CustomerId, e.TenantId })
.HasFilter("\"is_deleted\" = false");
Search/filter (endpoint có query parameters):
// Nếu endpoint cho phép filter theo status + date range
builder.HasIndex(e => new { e.TenantId, e.Status, e.CreatedAt });
Migration cho expression index
public partial class AddExpressionIndexes : Migration
{
protected override void Up(MigrationBuilder migrationBuilder)
{
migrationBuilder.Sql(@"
CREATE INDEX idx_customers_email_lower
ON customers (LOWER(email))
WHERE is_deleted = false;
CREATE INDEX idx_products_search
ON products USING GIN (to_tsvector('english', name || ' ' || description))
WHERE is_deleted = false;
");
}
protected override void Down(MigrationBuilder migrationBuilder)
{
migrationBuilder.Sql(@"
DROP INDEX IF EXISTS idx_customers_email_lower;
DROP INDEX IF EXISTS idx_products_search;
");
}
}
REINDEX và VACUUM — Maintenance index
Index bị "phình" (bloat) theo thời gian khi có nhiều UPDATE/DELETE. PostgreSQL giữ dead tuples trong index cho đến khi VACUUM chạy.
-- Kiểm tra index bloat
SELECT
indexrelname,
pg_size_pretty(pg_relation_size(indexrelid)) AS index_size,
idx_scan
FROM pg_stat_user_indexes
WHERE relname = 'invoices'
ORDER BY pg_relation_size(indexrelid) DESC;
-- Rebuild index (lock table!)
REINDEX INDEX idx_invoices_tenant_status_created;
-- Rebuild concurrent (không lock, PostgreSQL 12+)
REINDEX INDEX CONCURRENTLY idx_invoices_tenant_status_created;
REINDEX CONCURRENTLY không lock table — dùng trên production. REINDEX thường lock table — chỉ dùng khi maintenance window.
Autovacuum mặc định bật — nó tự clean dead tuples. Nhưng bảng có write-heavy workload có thể cần tune autovacuum parameters:
-- Tune autovacuum cho bảng cụ thể
ALTER TABLE invoices SET (
autovacuum_vacuum_scale_factor = 0.05, -- vacuum khi 5% rows dead (default 20%)
autovacuum_analyze_scale_factor = 0.02 -- analyze khi 2% rows changed
);
Checklist tối ưu index
Khi optimize query performance, mình theo workflow sau. Bước đầu tiên: chạy EXPLAIN ANALYZE cho slow query, hiểu execution plan hiện tại. Bước hai: xác định columns trong WHERE, JOIN, ORDER BY. Bước ba: tạo composite index với equality columns trước, range columns sau, sort column cuối. Bước bốn: thêm partial filter nếu có soft delete hoặc tenant filter. Bước năm: chạy lại EXPLAIN ANALYZE, confirm index được sử dụng và thời gian giảm. Bước sáu: test với data thật (không phải 100 records test, mà volume gần production). Bước cuối: monitor pg_stat_user_indexes sau 1-2 tuần — index có thực sự được dùng không.
Kết luận
Index strategy không phải đoán mò. Bắt đầu từ EXPLAIN ANALYZE, hiểu query đang chạy thế nào, rồi mới quyết định cần index gì. Composite index với thứ tự columns đúng giải quyết 80% vấn đề performance. Partial index cho soft delete và multi-tenant. GIN cho JSONB và full-text search. INCLUDE columns cho covering index khi cần tối ưu thêm.
Và quan trọng nhất: không phải mọi query đều cần index. Bảng nhỏ, query chạy ít, write-heavy table — đôi khi không có index lại tốt hơn. Đo lường trước và sau, bằng EXPLAIN ANALYZE, không bằng cảm giác.

Leave a comment
Your email address will not be published. Required fields are marked *