Có một kiểu bug mà mình sợ nhất: "app bỗng dưng chậm". Không error log, không exception, không crash. Chỉ là mọi thứ chậm đi. Response time từ 50ms lên 2 giây. User bắt đầu complain. Team nhìn nhau — code không ai sửa gì, deploy cũng không, server CPU bình thường.
Mười lần gặp kiểu này thì chín lần nguyên nhân ở database. Query từng nhanh giờ chậm vì data tăng mà index không đủ. Lock contention vì hai feature mới cùng update một bảng. Table bloat vì autovacuum lag. Connection pool hết vì query chạy lâu giữ connection.
PostgreSQL ghi lại TẤT CẢ những gì xảy ra bên trong — qua hệ thống pg_stat_* views. Vấn đề là ít developer biết đọc. Bài viết này đi qua từng view quan trọng, kèm query mẫu copy-paste được, và quy trình chẩn đoán từ "app chậm" đến "đây là nguyên nhân, đây là cách fix".
pg_stat_statements — tìm slow query
Đây là view quan trọng nhất. Nó ghi lại mọi query từng chạy qua PostgreSQL: chạy bao nhiêu lần, tổng thời gian bao lâu, trung bình bao lâu, đọc bao nhiêu block. Là thứ đầu tiên mình xem khi database chậm.
Bật extension
-- cần superuser
CREATE EXTENSION IF NOT EXISTS pg_stat_statements;
-- verify
SELECT * FROM pg_stat_statements LIMIT 1;
Nếu không có quyền CREATE EXTENSION, bảo DBA bật. Extension này gần như zero overhead — nên bật mặc định trên mọi production database.
# postgresql.conf — optional tuning
shared_preload_libraries = 'pg_stat_statements'
pg_stat_statements.max = 10000 # track tối đa 10k query patterns
pg_stat_statements.track = top # chỉ track top-level statements
Query tìm top slow queries
-- Top 20 query tốn thời gian nhất (tổng)
SELECT
queryid,
LEFT(query, 80) AS query_preview,
calls,
ROUND(total_exec_time::numeric, 1) AS total_ms,
ROUND(mean_exec_time::numeric, 2) AS avg_ms,
ROUND((100.0 * total_exec_time / SUM(total_exec_time) OVER ())::numeric, 1)
AS pct_total_time,
rows
FROM pg_stat_statements
WHERE dbname = current_database()
ORDER BY total_exec_time DESC
LIMIT 20;
Output ví dụ:
query_preview | calls | total_ms | avg_ms | pct_total_time
--------------------------------------------------+--------+----------+--------+---------------
SELECT * FROM orders WHERE customer_id = $1 | 45200 | 561000 | 12.4 | 32.1%
SELECT p.*, c.name FROM products p JOIN cate... | 128000 | 410000 | 3.2 | 23.5%
UPDATE inventory SET qty = qty - $1 WHERE sku... | 12800 | 111000 | 8.7 | 6.4%
SELECT COUNT(*) FROM audit_logs WHERE created... | 2100 | 94500 | 45.0 | 5.4%
Đọc kết quả:
- Query đầu tiên chiếm 32% tổng thời gian database — optimize cái này impact lớn nhất
avg_ms = 12.4không tệ, nhưngcalls = 45,200nhân lên thành 561 giây — N+1 query pattern?- Query cuối
avg_ms = 45gọi ít nhưng mỗi lần rất chậm — thiếu index trênaudit_logs.created_at?
Phân loại query theo pattern
-- query nào gọi nhiều nhất (hot path)
SELECT LEFT(query, 60), calls, mean_exec_time
FROM pg_stat_statements
WHERE dbname = current_database()
ORDER BY calls DESC
LIMIT 10;
-- query nào đọc nhiều data nhất (I/O heavy)
SELECT LEFT(query, 60), calls,
shared_blks_hit + shared_blks_read AS total_blocks,
ROUND(100.0 * shared_blks_hit /
NULLIF(shared_blks_hit + shared_blks_read, 0), 1) AS cache_hit_pct
FROM pg_stat_statements
WHERE dbname = current_database()
ORDER BY (shared_blks_hit + shared_blks_read) DESC
LIMIT 10;
cache_hit_pct dưới 95% cho một query = query đó đang đọc từ disk nhiều. Cần index hoặc table quá lớn cho shared_buffers.
Reset stats khi cần so sánh
-- reset để đo lại từ đầu (sau khi deploy, sau khi optimize)
SELECT pg_stat_statements_reset();
Reset trước deploy, chờ 1 giờ traffic, rồi query lại — thấy ngay deploy mới ảnh hưởng thế nào đến query patterns.
pg_stat_activity — ai đang làm gì trên database
Khi database đang chậm ngay LÚC NÀY — không cần stats quá khứ, cần biết hiện tại chuyện gì đang xảy ra:
-- queries đang chạy, sort theo thời gian chạy (lâu nhất trước)
SELECT
pid,
now() - query_start AS duration,
state,
wait_event_type,
wait_event,
LEFT(query, 80) AS query,
usename,
client_addr
FROM pg_stat_activity
WHERE state != 'idle'
AND pid != pg_backend_pid() -- bỏ qua chính query này
ORDER BY query_start ASC;
Output khi database có vấn đề:
pid | duration | state | wait_event_type | wait_event | query
------+-----------+--------+-----------------+---------------+------------------------------------------
1234 | 00:05:12 | active | Lock | transactionid | UPDATE orders SET status = 'shipped'...
1235 | 00:05:10 | active | Lock | transactionid | UPDATE orders SET status = 'paid'...
1236 | 00:04:58 | active | Lock | tuple | UPDATE orders SET total = ...
1240 | 00:00:03 | active | | | SELECT * FROM products WHERE...
Ba query đầu đang chờ lock hơn 5 phút — đây là lock contention. Một transaction giữ lock trên orders table, ba transaction khác xếp hàng chờ.
Tìm blocker — ai đang block ai
-- tìm transaction đang block người khác
SELECT
blocked.pid AS blocked_pid,
blocked.query AS blocked_query,
blocking.pid AS blocking_pid,
blocking.query AS blocking_query,
now() - blocked.query_start AS blocked_duration
FROM pg_stat_activity blocked
JOIN pg_stat_activity blocking
ON blocking.pid = ANY(pg_blocking_pids(blocked.pid))
WHERE blocked.pid != blocked.pid; -- trick to avoid self-join issues
-- simplified version
SELECT
pid,
pg_blocking_pids(pid) AS blocked_by,
LEFT(query, 60) AS query,
now() - query_start AS duration,
wait_event
FROM pg_stat_activity
WHERE cardinality(pg_blocking_pids(pid)) > 0;
pg_blocking_pids(pid) — function built-in trả về danh sách PID đang block process này. Từ đây biết ngay nên cancel/terminate PID nào.
Kill long-running query
-- cancel query (nhẹ nhàng — query nhận cancel request)
SELECT pg_cancel_backend(1234);
-- terminate connection (mạnh — đóng connection luôn)
SELECT pg_terminate_backend(1234);
pg_cancel_backend cancel query hiện tại nhưng giữ connection. pg_terminate_backend kill cả connection — dùng khi cancel không đủ.
Connection monitoring
-- đếm connection theo state
SELECT
state,
usename,
COUNT(*) AS connections,
MAX(now() - state_change) AS longest_in_state
FROM pg_stat_activity
GROUP BY state, usename
ORDER BY connections DESC;
Output khi connection pool hết:
state | usename | connections | longest_in_state
-------------------+---------+-------------+-----------------
idle | app | 85 | 00:45:00
active | app | 12 | 00:00:01
idle in transaction| app | 3 | 00:12:34
idle in transaction = connection mở transaction nhưng không làm gì. 3 connection "idle in transaction" trong 12 phút = leak. Đâu đó trong code mở transaction mà không commit/rollback. Đây là nguồn gốc phổ biến nhất của connection exhaustion.
-- tìm idle in transaction connections
SELECT pid, usename, state, LEFT(query, 60),
now() - xact_start AS transaction_duration,
now() - state_change AS idle_duration
FROM pg_stat_activity
WHERE state = 'idle in transaction'
ORDER BY xact_start;
Fix trong .NET: đảm bảo mọi DbContext được dispose (dùng using hoặc DI scope), và set Idle In Transaction Session Timeout:
ALTER DATABASE mydb SET idle_in_transaction_session_timeout = '60s';
-- kill connection idle in transaction quá 60 giây
pg_stat_user_tables — health check từng bảng
-- overview health cho mọi bảng
SELECT
schemaname || '.' || relname AS table_name,
pg_size_pretty(pg_total_relation_size(relid)) AS total_size,
n_live_tup AS live_rows,
n_dead_tup AS dead_rows,
ROUND(100.0 * n_dead_tup / NULLIF(n_live_tup + n_dead_tup, 0), 1)
AS dead_pct,
last_vacuum,
last_autovacuum,
last_analyze,
seq_scan,
idx_scan,
CASE WHEN seq_scan + idx_scan > 0
THEN ROUND(100.0 * idx_scan / (seq_scan + idx_scan), 1)
ELSE 0 END AS idx_scan_pct
FROM pg_stat_user_tables
ORDER BY n_dead_tup DESC;
Đọc kết quả — mỗi metric là một signal:
dead_pct > 20% — table bloat. Autovacuum chưa kịp dọn dead tuples. Cần tune autovacuum hoặc chạy VACUUM ANALYZE thủ công.
-- chạy vacuum cho bảng cụ thể
VACUUM (VERBOSE, ANALYZE) orders;
last_autovacuum = NULL — autovacuum chưa bao giờ chạy cho bảng này. Bảng nhỏ thì không sao, bảng lớn có nhiều UPDATE/DELETE thì nguy hiểm.
seq_scan cao + idx_scan thấp — bảng đang bị sequential scan nhiều. Thiếu index hoặc query không dùng index.
-- bảng nào bị seq scan nhiều nhất (cần index)
SELECT
relname,
seq_scan,
idx_scan,
seq_scan - idx_scan AS seq_minus_idx,
n_live_tup
FROM pg_stat_user_tables
WHERE n_live_tup > 10000 -- chỉ bảng lớn
ORDER BY seq_scan - idx_scan DESC
LIMIT 10;
Bảng 500k rows mà seq_scan = 45000, idx_scan = 200? Gần như mọi query đều scan toàn bảng. Check query pattern → thêm index.
pg_stat_user_indexes — index nào đang dùng, cái nào thừa
-- index không ai dùng (lãng phí disk + slow write)
SELECT
schemaname || '.' || indexrelname AS index_name,
relname AS table_name,
pg_size_pretty(pg_relation_size(indexrelid)) AS index_size,
idx_scan AS times_used,
idx_tup_read,
idx_tup_fetch
FROM pg_stat_user_indexes
WHERE idx_scan = 0 -- chưa bao giờ được dùng
AND indexrelname NOT LIKE '%pkey' -- bỏ qua PK
AND indexrelname NOT LIKE '%unique%'
ORDER BY pg_relation_size(indexrelid) DESC;
Index 200MB mà idx_scan = 0? Xóa bớt — mỗi INSERT/UPDATE phải maintain index đó, tốn write performance và disk space vô ích.
-- trước khi xóa, double check bằng pg_stat_statements
-- query nào reference bảng đó có dùng index không
SELECT LEFT(query, 80), calls, mean_exec_time
FROM pg_stat_statements
WHERE query ILIKE '%orders%'
ORDER BY calls DESC LIMIT 10;
-- index nào hữu ích nhất (đọc nhiều nhất)
SELECT
indexrelname AS index_name,
relname AS table_name,
idx_scan,
pg_size_pretty(pg_relation_size(indexrelid)) AS size
FROM pg_stat_user_indexes
ORDER BY idx_scan DESC
LIMIT 10;
EXPLAIN ANALYZE — hiểu query plan thật sự
pg_stat_statements cho biết QUERY NÀO chậm. EXPLAIN ANALYZE cho biết TẠI SAO nó chậm.
Cú pháp đầy đủ
EXPLAIN (ANALYZE, BUFFERS, FORMAT TEXT)
SELECT o.*, c.name AS customer_name
FROM orders o
JOIN customers c ON o.customer_id = c.id
WHERE o.status = 'pending'
AND o.created_at > NOW() - INTERVAL '7 days'
ORDER BY o.created_at DESC
LIMIT 20;
ANALYZE — chạy query thật, đo thời gian thật (không chỉ estimate). BUFFERS — cho biết đọc bao nhiêu page từ cache vs disk.
Đọc output — pattern phổ biến
Pattern 1: Seq Scan trên bảng lớn
Seq Scan on orders (cost=0.00..15234.00 rows=500000 width=120)
(actual time=0.012..245.000 rows=500000 loops=1)
Filter: (status = 'pending')
Rows Removed by Filter: 480000
Buffers: shared hit=8234
Rows Removed by Filter: 480000 — quét 500k row để lấy 20k row. Index trên status sẽ skip 480k row đó:
CREATE INDEX idx_orders_status ON orders (status)
WHERE status IN ('pending', 'processing');
-- partial index — chỉ index status mà hay query
Sau index:
Index Scan using idx_orders_status on orders (cost=0.29..852.00 rows=20000 width=120)
(actual time=0.015..3.200 rows=20000 loops=1)
Index Cond: (status = 'pending')
Buffers: shared hit=156
245ms → 3.2ms. 8234 buffer reads → 156. Một index thay đổi 80 lần performance.
Pattern 2: Nested Loop quá nhiều
Nested Loop (actual time=0.030..4521.000 rows=50000)
-> Seq Scan on orders (actual time=0.010..12.000 rows=1000)
-> Index Scan on order_items (actual time=0.002..4.500 rows=50 loops=1000)
loops=1000 — inner scan chạy 1000 lần. Đây là N+1 pattern ở database level. Nếu bạn thấy loops cao trong Nested Loop, check application code — có thể đang query trong loop.
Pattern 3: Sort external
Sort (actual time=456.000..489.000 rows=100000)
Sort Key: created_at
Sort Method: external merge Disk: 15640kB
external merge Disk — data không fit trong work_mem, phải sort trên disk. Chậm gấp nhiều lần in-memory sort.
-- tăng work_mem cho session (cẩn thận, mỗi sort dùng work_mem riêng)
SET work_mem = '256MB'; -- mặc định 4MB
Hoặc thêm index bao gồm sort column:
CREATE INDEX idx_orders_created ON orders (created_at DESC);
-- giờ ORDER BY created_at DESC dùng index scan, không cần sort
Pattern 4: Hash Join build lớn
Hash Join (actual time=234.000..567.000 rows=50000)
Hash Cond: (o.customer_id = c.id)
-> Seq Scan on orders o (actual time=0.010..120.000 rows=500000)
-> Hash (actual time=112.000..112.000 rows=100000)
Buckets: 131072 Memory Usage: 8234kB
Hash build 112ms + probe 455ms. Nếu Memory Usage lớn hơn work_mem, hash spill xuống disk. Tăng work_mem hoặc giảm data set bằng filter trước JOIN.
Auto EXPLAIN cho mọi slow query
-- bật auto_explain — tự log plan cho query chậm
LOAD 'auto_explain';
SET auto_explain.log_min_duration = '200ms'; -- log plan cho query > 200ms
SET auto_explain.log_buffers = true;
SET auto_explain.log_analyze = true;
Mọi query chậm hơn 200ms tự động ghi execution plan vào PostgreSQL log. Không cần EXPLAIN thủ công — mở log là thấy.
Wait Events — database đang chờ gì
-- queries đang chờ, group theo loại wait
SELECT
wait_event_type,
wait_event,
COUNT(*) AS count,
ARRAY_AGG(DISTINCT LEFT(query, 40)) AS sample_queries
FROM pg_stat_activity
WHERE wait_event IS NOT NULL
AND state = 'active'
GROUP BY wait_event_type, wait_event
ORDER BY count DESC;
Wait event types thường gặp:
Lock / transactionid — transaction A chờ transaction B commit/rollback. Thường do long transaction hoặc hot row contention.
IO / DataFileRead — đọc data từ disk. shared_buffers quá nhỏ, hoặc working set lớn hơn RAM.
LWLock / BufferMapping — contention trên shared buffer. Nhiều connection cùng truy cập hot page.
Client / ClientRead — database chờ client gửi data. Application chậm hoặc network lag.
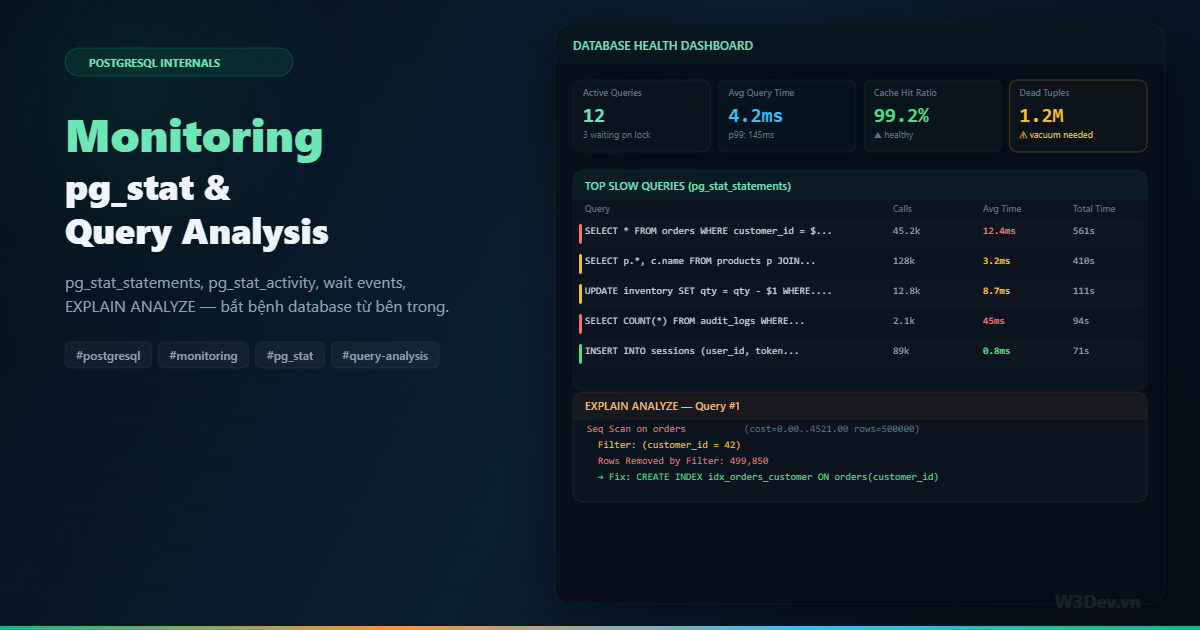
Dashboard query — chạy định kỳ
Mình tạo một script chạy mỗi sáng (hoặc cron mỗi giờ) để health check:
-- 1. Overall database health
SELECT
'Database Size' AS metric,
pg_size_pretty(pg_database_size(current_database())) AS value
UNION ALL
SELECT 'Active Connections',
COUNT(*)::text FROM pg_stat_activity WHERE state = 'active'
UNION ALL
SELECT 'Idle in Transaction',
COUNT(*)::text FROM pg_stat_activity WHERE state = 'idle in transaction'
UNION ALL
SELECT 'Cache Hit Ratio',
ROUND(100.0 * SUM(blks_hit) / NULLIF(SUM(blks_hit + blks_read), 0), 2)::text || '%'
FROM pg_stat_database WHERE datname = current_database()
UNION ALL
SELECT 'Transaction Commits/s',
ROUND(xact_commit::numeric / GREATEST(EXTRACT(EPOCH FROM now() - stats_reset), 1), 1)::text
FROM pg_stat_database WHERE datname = current_database()
UNION ALL
SELECT 'Total Dead Tuples',
SUM(n_dead_tup)::text FROM pg_stat_user_tables;
-- 2. Tables needing attention
SELECT relname, n_dead_tup, last_autovacuum,
pg_size_pretty(pg_total_relation_size(relid))
FROM pg_stat_user_tables
WHERE n_dead_tup > 100000
OR last_autovacuum < NOW() - INTERVAL '7 days'
ORDER BY n_dead_tup DESC;
-- 3. Index health
SELECT COUNT(*) AS unused_indexes,
pg_size_pretty(SUM(pg_relation_size(indexrelid))) AS wasted_space
FROM pg_stat_user_indexes
WHERE idx_scan = 0
AND indexrelname NOT LIKE '%pkey';
Alert thresholds
Mình set alert cho các ngưỡng:
Cache hit ratio < 95% → ⚠ shared_buffers quá nhỏ
Dead tuple ratio > 20% → ⚠ vacuum cần chạy
Idle in transaction > 5 min → ⚠ transaction leak
Active connections > 80% max → ⚠ connection pool sắp hết
Seq scan / idx scan > 50% → ⚠ missing index
Query avg time > 100ms → ⚠ slow query cần optimize
Tích hợp monitoring vào .NET
Health check endpoint
public class DatabaseHealthCheck : IHealthCheck
{
private readonly AppDbContext _db;
public DatabaseHealthCheck(AppDbContext db) => _db = db;
public async Task<HealthCheckResult> CheckHealthAsync(
HealthCheckContext context, CancellationToken ct = default)
{
try
{
// basic connectivity
await _db.Database.ExecuteSqlRawAsync("SELECT 1", ct);
// check critical metrics
var stats = await _db.Database
.SqlQuery<DbHealthStats>($"""
SELECT
(SELECT COUNT(*) FROM pg_stat_activity
WHERE state = 'idle in transaction'
AND now() - xact_start > interval '5 min')
AS long_idle_transactions,
(SELECT COALESCE(
ROUND(100.0 * SUM(blks_hit) /
NULLIF(SUM(blks_hit + blks_read), 0), 1), 0)
FROM pg_stat_database
WHERE datname = current_database())
AS cache_hit_ratio,
(SELECT COUNT(*) FROM pg_stat_activity
WHERE state != 'idle')
AS active_connections
""")
.SingleAsync(ct);
var data = new Dictionary<string, object>
{
["cache_hit_ratio"] = stats.CacheHitRatio,
["active_connections"] = stats.ActiveConnections,
["long_idle_transactions"] = stats.LongIdleTransactions,
};
if (stats.CacheHitRatio < 90 || stats.LongIdleTransactions > 3)
return HealthCheckResult.Degraded("Database performance degraded", data: data);
return HealthCheckResult.Healthy("Database healthy", data);
}
catch (Exception ex)
{
return HealthCheckResult.Unhealthy("Database unreachable", ex);
}
}
}
record DbHealthStats(decimal CacheHitRatio, int ActiveConnections, int LongIdleTransactions);
Periodic stats collector
public class DbStatsCollector : BackgroundService
{
private readonly IServiceScopeFactory _scopeFactory;
private readonly ILogger<DbStatsCollector> _logger;
protected override async Task ExecuteAsync(CancellationToken ct)
{
while (!ct.IsCancellationRequested)
{
try
{
using var scope = _scopeFactory.CreateScope();
var db = scope.ServiceProvider.GetRequiredService<AppDbContext>();
var slowQueries = await db.Database
.SqlQuery<SlowQueryInfo>($"""
SELECT LEFT(query, 200) AS query_text,
calls, mean_exec_time AS avg_ms,
total_exec_time AS total_ms
FROM pg_stat_statements
WHERE mean_exec_time > 100
AND dbname = current_database()
ORDER BY total_exec_time DESC
LIMIT 5
""")
.ToListAsync(ct);
foreach (var q in slowQueries)
{
_logger.LogWarning(
"Slow query: avg={Avg}ms calls={Calls} total={Total}ms query={Query}",
q.AvgMs, q.Calls, q.TotalMs, q.QueryText);
}
}
catch (Exception ex)
{
_logger.LogError(ex, "Failed to collect DB stats");
}
await Task.Delay(TimeSpan.FromMinutes(15), ct);
}
}
}
Background service chạy mỗi 15 phút, log slow queries vào Seq/Application Insights. Không cần mở pgAdmin — slow query alert tự đến dashboard.
Quy trình chẩn đoán: "App chậm" → Root cause
Mỗi khi gặp performance issue, mình follow quy trình này:
Bước 1: pg_stat_activity
→ Có query nào đang chạy lâu bất thường?
→ Có lock contention không?
→ Có "idle in transaction" leak không?
Bước 2: pg_stat_statements
→ Top 5 query tốn thời gian nhất là gì?
→ Query nào có avg_time tăng so với tuần trước?
→ Query nào calls tăng đột biến?
Bước 3: pg_stat_user_tables
→ Bảng nào dead_tuples cao (vacuum lag)?
→ Bảng nào seq_scan >> idx_scan (missing index)?
Bước 4: EXPLAIN ANALYZE
→ Chạy EXPLAIN cho top slow query
→ Seq Scan trên bảng lớn? → Thêm index
→ Sort external? → Tăng work_mem hoặc thêm index
→ Nested Loop nhiều loops? → Check N+1 trong app
Bước 5: Verify fix
→ Thêm index → EXPLAIN lại → confirm Index Scan
→ Reset pg_stat_statements → chờ 1 giờ → so sánh
Năm bước, mỗi bước 5-10 phút. Phần lớn issue tìm ra trong 30 phút. Phần khó nhất không phải tìm — mà là biết xem ở đâu. Bài viết này cho bạn "xem ở đâu".
Tổng kết
PostgreSQL monitoring không cần tool đắt tiền. pg_stat_statements cho biết query nào chậm. pg_stat_activity cho biết hiện tại đang xảy ra gì. pg_stat_user_tables cho biết bảng nào cần attention. EXPLAIN ANALYZE cho biết tại sao query chậm. Bốn view, vài query, cover phần lớn performance diagnostics.
Hai thứ nên làm ngay nếu chưa: bật pg_stat_statements extension trên production database, và tạo health check endpoint đọc database stats. Khi vấn đề xảy ra, bạn đã có data để chẩn đoán thay vì bắt đầu từ con số không.

Leave a comment
Your email address will not be published. Required fields are marked *