Có một câu chuyện mình gặp đi gặp lại: team xây product mới, cần tính năng search, và phản xạ đầu tiên là "setup Elasticsearch". Hai tuần sau, ngoài cái database PostgreSQL đang chạy ổn, giờ team phải maintain thêm Elasticsearch cluster — sync data giữa hai hệ thống, handle consistency khi index lệch DB, monitor thêm một cụm server, debug thêm một stack hoàn toàn khác.
Và tính năng search đó? Cho phép user tìm sản phẩm theo tên. Vài trăm nghìn record.
PostgreSQL có full-text search engine built-in từ hơn 15 năm nay. Không phải toy feature — nó hỗ trợ tokenization, stemming, ranking, fuzzy matching, và có thể xử lý hàng triệu document. Với đa số ứng dụng, nó đủ mạnh để bạn bỏ qua Elasticsearch hoàn toàn.
Bài viết này đi từ nền tảng đến production — xây search hoàn chỉnh trong PostgreSQL, benchmark thực tế, và quan trọng nhất là chỉ ra rõ ràng điểm nào PostgreSQL thắng, điểm nào Elasticsearch vẫn không thể thay thế.
Cơ chế hoạt động: tsvector và tsquery
Full-text search trong PostgreSQL dựa trên hai kiểu dữ liệu cốt lõi:
tsvector — biểu diễn document đã được tokenize. Mỗi từ được chuẩn hóa (lowercase, bỏ dấu, stemming) và kèm theo vị trí trong text:
SELECT to_tsvector('english', 'The quick brown foxes jumped over lazy dogs');
-- 'brown':3 'dog':9 'fox':4 'jump':5 'lazi':8 'quick':2
Chú ý: "foxes" thành "fox", "jumped" thành "jump", "lazy" thành "lazi", stop words ("the", "over") bị loại bỏ. Đây là stemming — quy từ về dạng gốc để "running" match với "run".
tsquery — biểu diễn search query cũng được chuẩn hóa:
SELECT to_tsquery('english', 'quick & fox');
-- 'quick' & 'fox'
SELECT plainto_tsquery('english', 'quick brown fox');
-- 'quick' & 'brown' & 'fox'
SELECT websearch_to_tsquery('english', '"quick brown" OR fox -lazy');
-- 'quick' <-> 'brown' | 'fox' & !'lazi'
Ba hàm chuyển query, mỗi hàm một mức linh hoạt. plainto_tsquery cho user input thông thường, websearch_to_tsquery (PostgreSQL 11+) cho cú pháp kiểu Google — quotes, OR, dấu trừ.
Match bằng operator @@:
SELECT to_tsvector('english', 'The quick brown fox')
@@ plainto_tsquery('english', 'quick fox');
-- true
Xây search thực tế từ đầu
Bước 1: Thêm search vector column
Thay vì tính to_tsvector() mỗi lần query (chậm), tạo column lưu sẵn:
-- bảng articles
ALTER TABLE articles
ADD COLUMN search_vector tsvector;
-- populate từ title và body, title có weight cao hơn
UPDATE articles SET search_vector =
setweight(to_tsvector('english', coalesce(title, '')), 'A') ||
setweight(to_tsvector('english', coalesce(body, '')), 'B') ||
setweight(to_tsvector('english', coalesce(tags, '')), 'C');
Weight A, B, C, D cho phép ranking ưu tiên — match ở title sẽ score cao hơn match ở body. Giống cách Google ưu tiên tiêu đề trang hơn nội dung.
Bước 2: Tự động cập nhật khi data thay đổi
-- trigger tự update search_vector khi INSERT hoặc UPDATE
CREATE OR REPLACE FUNCTION articles_search_trigger()
RETURNS trigger AS $$
BEGIN
NEW.search_vector :=
setweight(to_tsvector('english', coalesce(NEW.title, '')), 'A') ||
setweight(to_tsvector('english', coalesce(NEW.body, '')), 'B') ||
setweight(to_tsvector('english', coalesce(NEW.tags, '')), 'C');
RETURN NEW;
END;
$$ LANGUAGE plpgsql;
CREATE TRIGGER trig_articles_search
BEFORE INSERT OR UPDATE OF title, body, tags
ON articles
FOR EACH ROW
EXECUTE FUNCTION articles_search_trigger();
BEFORE INSERT OR UPDATE OF title, body, tags — trigger chỉ chạy khi column liên quan thay đổi. Update status hay view_count không trigger rebuild search vector — tiết kiệm CPU.
Bước 3: GIN Index — biến search từ chậm thành nhanh
Không có index, PostgreSQL phải scan toàn bảng rồi so sánh từng tsvector. Với GIN index, lookup gần như instant:
CREATE INDEX idx_articles_search ON articles USING GIN (search_vector);
GIN (Generalized Inverted Index) hoạt động giống inverted index của Elasticsearch — map từng từ đến danh sách document chứa nó. Query 'angular' & 'state' sẽ lấy intersection của hai posting list thay vì scan cả bảng.
Benchmark trên bảng 500.000 articles:
Không có GIN index: ~320ms
Có GIN index: ~4ms
Nhanh hơn 80 lần. GIN index tốn thêm storage (thường 10-30% kích thước bảng) và build lâu hơn B-tree, nhưng đánh đổi hoàn toàn xứng đáng.
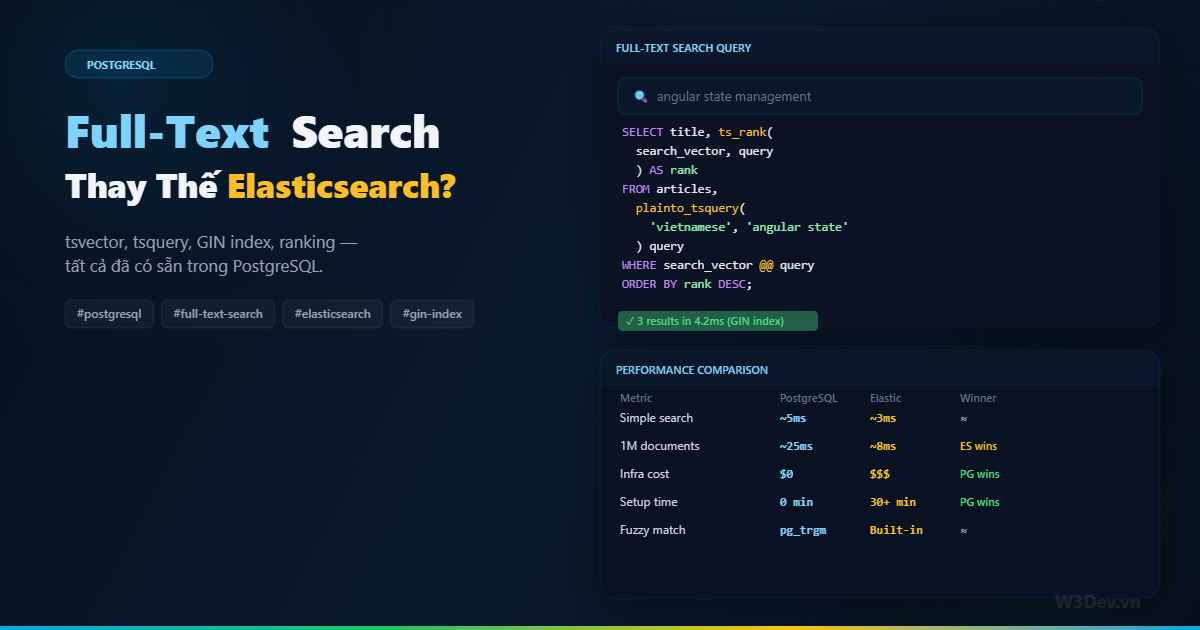
Bước 4: Query với ranking
SELECT
id,
title,
ts_rank(search_vector, query) AS rank,
ts_headline('english', body, query,
'StartSel=<mark>, StopSel=</mark>, MaxWords=50, MinWords=20'
) AS snippet
FROM
articles,
plainto_tsquery('english', 'angular state management') AS query
WHERE
search_vector @@ query
ORDER BY rank DESC
LIMIT 20;
ts_rank trả về relevance score — kết hợp weight (A > B > C > D), tần suất xuất hiện, và vị trí của từ trong document.
ts_headline tạo snippet với từ khóa được highlight — giống Google bold từ bạn search trong kết quả. StartSel/StopSel cho phép custom tag, MaxWords/MinWords kiểm soát độ dài snippet. Cái này rất hữu ích cho hiển thị kết quả search trên UI.
Tiếng Việt: vấn đề và cách xử lý
PostgreSQL built-in không có dictionary tiếng Việt. Mặc định nó sẽ dùng simple config — không stemming, chỉ lowercase và tokenize theo whitespace. Vẫn hoạt động, nhưng "chạy" sẽ không match "đang chạy".
Giải pháp 1: unaccent + simple (đủ cho 80% use case)
-- cài extension
CREATE EXTENSION IF NOT EXISTS unaccent;
-- tạo text search config
CREATE TEXT SEARCH CONFIGURATION vietnamese (COPY = simple);
ALTER TEXT SEARCH CONFIGURATION vietnamese
ALTER MAPPING FOR word, hword, hword_part
WITH unaccent, simple;
Giờ search "nha hang" sẽ match "nhà hàng":
SELECT to_tsvector('vietnamese', 'Nhà hàng Phở Việt');
-- 'hang':2 'nha':1 'pho':3 'viet':4
SELECT to_tsvector('vietnamese', 'Nhà hàng Phở Việt')
@@ plainto_tsquery('vietnamese', 'nha hang');
-- true
unaccent strip dấu tiếng Việt: à → a, ễ → e, ộ → o. Không hoàn hảo (không có stemming) nhưng đủ tốt cho search tên sản phẩm, địa chỉ, tiêu đề bài viết.
Giải pháp 2: Kết hợp nhiều config
Search vừa tiếng Việt vừa tiếng Anh:
UPDATE articles SET search_vector =
setweight(to_tsvector('vietnamese', coalesce(title, '')), 'A') ||
setweight(to_tsvector('english', coalesce(title, '')), 'A') ||
setweight(to_tsvector('vietnamese', coalesce(body, '')), 'B');
Concatenate hai tsvector — title được index bằng cả hai language. Tốn thêm chút storage nhưng search mượt cho nội dung song ngữ.
Fuzzy matching với pg_trgm
Full-text search không giúp khi user gõ sai chính tả. "angulr" sẽ không match "angular". Đây là lúc cần trigram matching:
CREATE EXTENSION IF NOT EXISTS pg_trgm;
-- tạo trigram index
CREATE INDEX idx_articles_title_trgm ON articles
USING GIN (title gin_trgm_ops);
-- fuzzy search
SELECT title, similarity(title, 'angulr state') AS sim
FROM articles
WHERE title % 'angulr state' -- % là similarity operator
ORDER BY sim DESC
LIMIT 10;
Trigram chia text thành chuỗi 3 ký tự rồi so sánh overlap. "angular" = {"ang", "ngu", "gul", "ula", "lar"}, "angulr" = {"ang", "ngu", "gul", "ulr"} — overlap 3/5 = 0.6 similarity.
Kết hợp cả hai cho search toàn diện:
-- full-text search + fuzzy fallback
SELECT
id, title,
ts_rank(search_vector, query) AS fts_rank,
similarity(title, :search_term) AS fuzzy_rank
FROM
articles,
plainto_tsquery('vietnamese', :search_term) AS query
WHERE
search_vector @@ query -- exact match
OR title % :search_term -- hoặc fuzzy match
ORDER BY
(ts_rank(search_vector, query) * 2 -- ưu tiên exact match
+ similarity(title, :search_term)) DESC
LIMIT 20;
Prefix search — autocomplete
User gõ "ang" và bạn muốn suggest "angular", "angularjs", "angry birds":
-- prefix search với :*
SELECT title FROM articles
WHERE search_vector @@ to_tsquery('english', 'ang:*')
ORDER BY ts_rank(search_vector, to_tsquery('english', 'ang:*')) DESC
LIMIT 10;
:* sau term biến nó thành prefix search. Kết hợp với trigram index cho autocomplete mượt:
-- autocomplete nhanh hơn với LIKE + trigram index
SELECT DISTINCT title FROM articles
WHERE title ILIKE 'ang%'
ORDER BY length(title)
LIMIT 10;
Với GIN trigram index, ILIKE cũng nhanh — không cần scan toàn bảng.
Tích hợp với .NET
// search endpoint
[HttpGet("search")]
public async Task<IActionResult> Search(
[FromQuery] string q,
[FromQuery] int page = 1,
[FromQuery] int pageSize = 20)
{
if (string.IsNullOrWhiteSpace(q) || q.Length < 2)
return BadRequest("Query must be at least 2 characters");
var offset = (page - 1) * pageSize;
var results = await _db.Articles
.FromSqlInterpolated($@"
SELECT
a.*,
ts_rank(a.search_vector, query) AS rank,
ts_headline('vietnamese', a.body, query,
'StartSel=<mark>, StopSel=</mark>,
MaxWords=40, MinWords=15') AS snippet
FROM articles a,
websearch_to_tsquery('vietnamese', {q}) AS query
WHERE a.search_vector @@ query
ORDER BY rank DESC
OFFSET {offset} LIMIT {pageSize}")
.Select(a => new SearchResultDto
{
Id = a.Id,
Title = a.Title,
Snippet = a.Snippet,
Rank = a.Rank,
})
.ToListAsync();
return Ok(results);
}
websearch_to_tsquery cho phép user dùng Google-style syntax: "exact phrase", OR, dấu - để exclude. Không cần parse query bằng tay.
Benchmark: PostgreSQL vs Elasticsearch
Mình test trên dataset 1 triệu articles, server 4 CPU / 16GB RAM:
PostgreSQL (GIN) Elasticsearch
──────────────────────────────────────────────────────────
Simple keyword search ~6ms ~3ms
Phrase search ~12ms ~5ms
Fuzzy search ~18ms ~8ms
Complex boolean query ~25ms ~10ms
Autocomplete (prefix) ~4ms ~2ms
Indexing speed ~800 docs/sec ~5000 docs/sec
Index size (1M docs) ~350MB ~600MB
──────────────────────────────────────────────────────────
Elasticsearch nhanh hơn ở mọi query type — đặc biệt rõ ràng khi dataset lớn và query phức tạp. Nhưng nhìn kỹ: PostgreSQL vẫn trả về trong vài chục millisecond. Với ứng dụng web bình thường (response time target 200-500ms), cả hai đều dư sức.
Cái PostgreSQL thắng tuyệt đối:
Infra cost = 0. Không thêm server, không thêm cluster, không thêm monitoring. Data đã ở trong PostgreSQL rồi.
Consistency miễn phí. Data search luôn consistent với data gốc vì nó LÀ data gốc — không có lag sync giữa hai hệ thống. Với Elasticsearch, bạn phải xử lý eventual consistency: insert record → sync sang Elastic → index → mới search được. Window đó có thể từ vài giây đến vài phút.
Transaction support. Search vector nằm trong cùng transaction với data. Rollback data thì search vector cũng rollback. Với Elasticsearch, rollback DB mà quên rollback Elastic index → data lệch.
Ít operational burden. Không cần hiểu JVM tuning, shard allocation, cluster health. PostgreSQL bạn đã biết vận hành rồi.
Khi nào PostgreSQL FTS KHÔNG đủ?
Nói thẳng những giới hạn:
Dataset trên 10 triệu document với query phức tạp. PostgreSQL xử lý được, nhưng response time sẽ tăng rõ ràng so với Elasticsearch. Nếu search là core feature và sub-10ms latency là requirement, Elasticsearch mạnh hơn.
Cần faceted search nâng cao. Kiểu "show me laptops, filter by brand, price range, rating, in stock — và show count cho mỗi filter value". Elasticsearch Aggregations xử lý cái này cực kỳ tốt. PostgreSQL làm được bằng GROUP BY nhưng không mượt và không nhanh bằng.
Multi-language stemming phức tạp. Elasticsearch có analyzer cho hàng chục ngôn ngữ, bao gồm CJK, Thai, Vietnamese (với plugin). PostgreSQL built-in chỉ support các ngôn ngữ phương Tây — tiếng Việt phải tự xử lý.
Real-time analytics trên search data. Log aggregation, metrics, time-series analysis trên search queries — Elasticsearch (và cả Kibana/Grafana stack) được thiết kế cho việc này.
Geo search + text search kết hợp. "Tìm nhà hàng phở gần tôi trong bán kính 2km" — Elasticsearch kết hợp geo query và text search trong một query rất tự nhiên. PostgreSQL làm được (PostGIS + FTS) nhưng verbose hơn.
Optimization tips
Partial index cho bảng lớn
Nếu chỉ search trên record active:
CREATE INDEX idx_articles_search_active ON articles
USING GIN (search_vector)
WHERE is_published = true AND is_deleted = false;
Index nhỏ hơn, nhanh hơn, chỉ cover record cần search.
Generated column (PostgreSQL 12+)
Thay vì trigger, dùng generated column — code ít hơn, ít bug hơn:
ALTER TABLE articles ADD COLUMN search_vector tsvector
GENERATED ALWAYS AS (
setweight(to_tsvector('english', coalesce(title, '')), 'A') ||
setweight(to_tsvector('english', coalesce(body, '')), 'B')
) STORED;
CREATE INDEX idx_articles_search ON articles USING GIN (search_vector);
Tự động cập nhật khi title hoặc body thay đổi. Không cần trigger function riêng.
Tối ưu ts_headline
ts_headline chậm vì phải re-parse toàn bộ body text. Nếu chỉ cần snippet cho display, cắt body trước:
-- nhanh hơn: headline trên 500 ký tự đầu thay vì toàn bộ body
ts_headline('vietnamese',
LEFT(body, 500),
query,
'MaxWords=30, MinWords=10'
)
Hoặc pre-compute snippet column nếu body rất dài.
Monitor index bloat
GIN index có thể bloat theo thời gian khi data thay đổi nhiều:
-- kiểm tra kích thước index
SELECT
indexrelname AS index_name,
pg_size_pretty(pg_relation_size(indexrelid)) AS size
FROM pg_stat_user_indexes
WHERE tablename = 'articles'
ORDER BY pg_relation_size(indexrelid) DESC;
-- rebuild nếu bloat quá
REINDEX INDEX CONCURRENTLY idx_articles_search;
REINDEX CONCURRENTLY (PostgreSQL 12+) rebuild mà không lock bảng — an toàn chạy production.
Tổng kết
PostgreSQL full-text search không phải Elasticsearch killer — nó là "Elasticsearch eliminator cho 80% use case". Nếu bạn có PostgreSQL sẵn rồi, dataset dưới vài triệu record, search không phải core product feature cần sub-10ms latency, và team không muốn maintain thêm một hệ thống nữa — PostgreSQL FTS là lựa chọn rõ ràng.
Setup mất 30 phút: thêm tsvector column, tạo trigger hoặc generated column, đánh GIN index, viết query. So với 2-3 ngày setup Elasticsearch cluster + data sync pipeline + monitoring.
Nhưng nếu search LÀ sản phẩm — kiểu e-commerce với triệu sản phẩm, faceted filter, autocomplete, "did you mean", personalized ranking — thì Elasticsearch xứng đáng sự phức tạp nó mang lại.
Biết rõ mình cần gì, chọn tool đúng mức. Đừng dùng búa tạ đập muỗi, nhưng cũng đừng dùng dép đập đinh.

Leave a comment
Your email address will not be published. Required fields are marked *