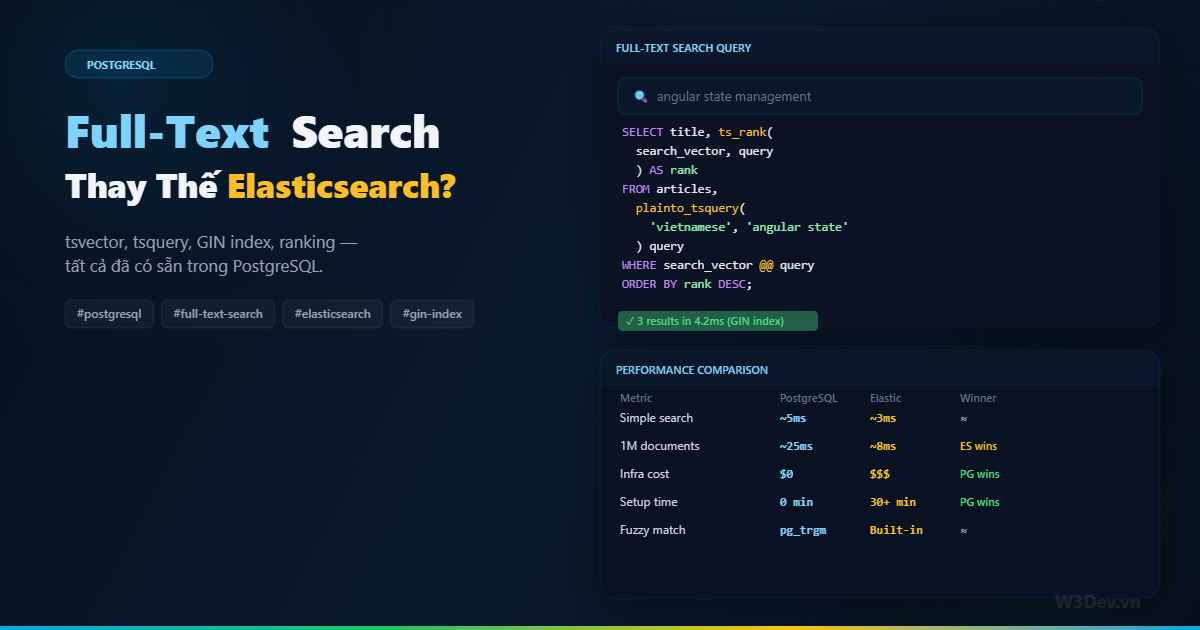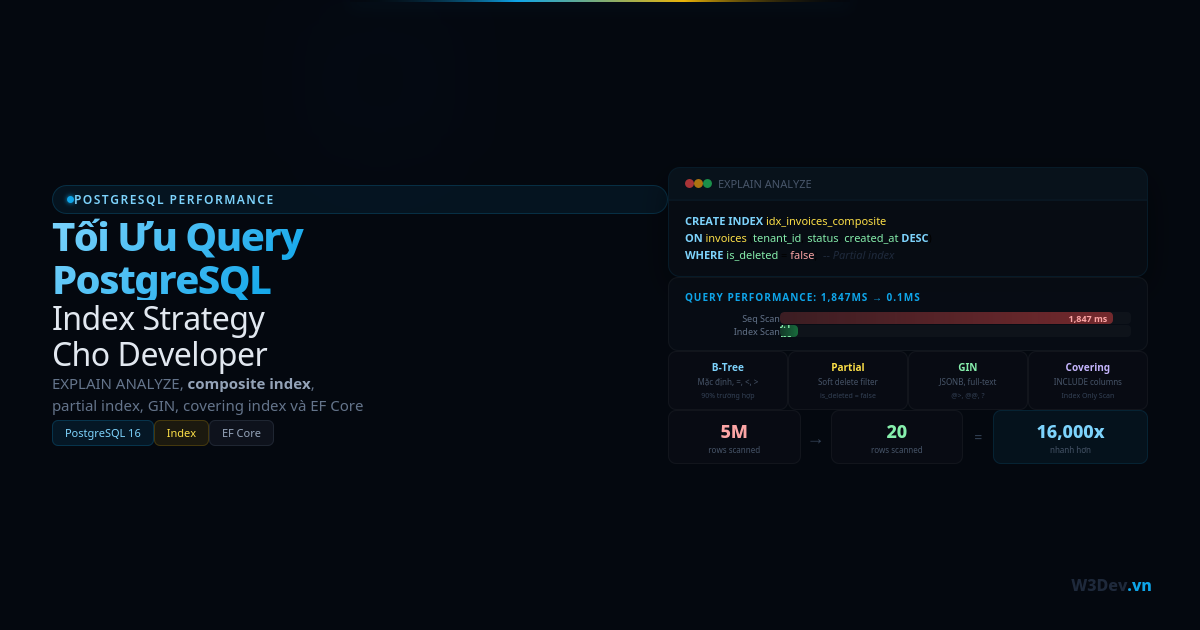
Bảng orders của bạn vừa chạm mốc 200 triệu row. Query SELECT ... WHERE created_at BETWEEN ... mà trước đây chạy 50ms giờ lên 8 giây. VACUUM chạy hàng tiếng. Index rebuild thì phải chọn lúc 3 giờ sáng vì lock cả bảng. DBA bảo "partition đi" nhưng không ai biết bắt đầu từ đâu.
Đó là tình huống mình gặp cách đây hai năm. Và bài viết này là tổng hợp những gì mình đã học được — cả từ documentation lẫn từ những lần sai.
Partitioning là gì?
Nói đơn giản: partitioning là chia một bảng lớn thành nhiều bảng con nhỏ hơn, nhưng vẫn truy vấn qua một "cửa" duy nhất. Application code không cần biết data nằm ở partition nào — PostgreSQL tự route query đến đúng partition.
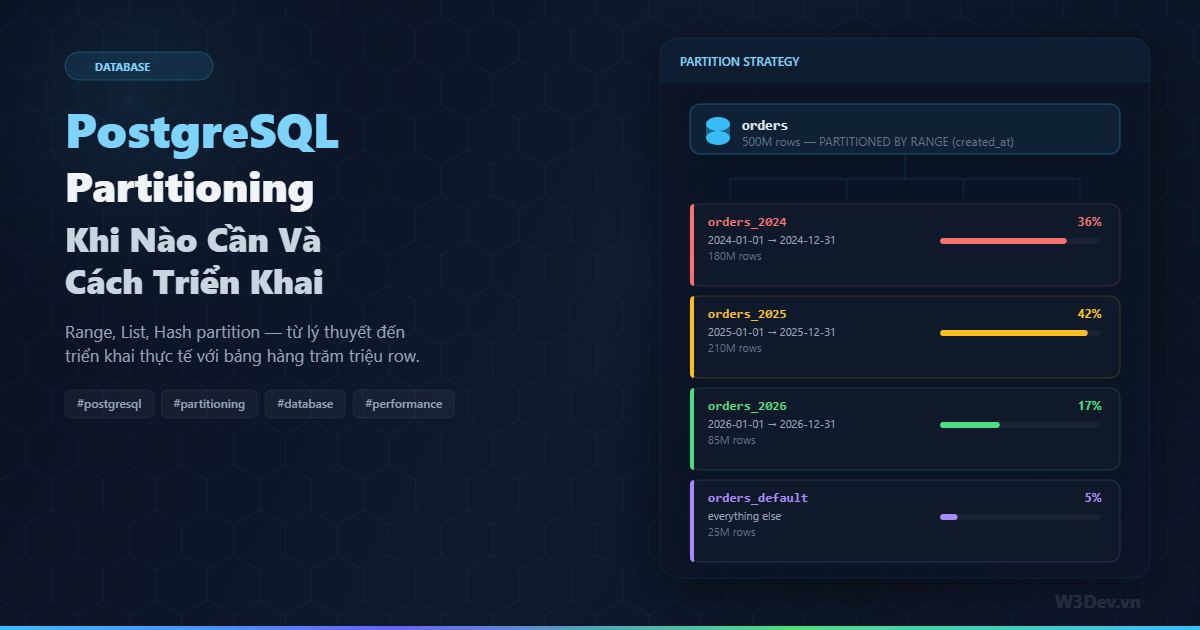
orders (parent — bảng logic, không chứa data)
├── orders_2024 (data từ 2024-01-01 đến 2024-12-31)
├── orders_2025 (data từ 2025-01-01 đến 2025-12-31)
├── orders_2026 (data từ 2026-01-01 đến 2026-12-31)
└── orders_default (mọi thứ không thuộc partition nào)
Khi bạn chạy SELECT * FROM orders WHERE created_at = '2025-06-15', PostgreSQL chỉ scan bảng orders_2025 thay vì quét toàn bộ 500 triệu row. Cơ chế này gọi là partition pruning — và nó là lý do chính khiến partitioning nhanh.
Khi nào thì cần partition?
Đây là câu hỏi quan trọng nhất, vì partition không phải lúc nào cũng tốt. Nó thêm complexity vào hệ thống, và nếu dùng sai thì performance có thể còn tệ hơn.
Mình khuyên nên partition khi ít nhất hai trong những điều sau đúng:
Bảng có trên 50-100 triệu row và đang tăng liên tục. Dưới mức này, index tốt là đủ. PostgreSQL handle index trên bảng vài chục triệu row rất ổn — đừng over-engineer.
Query hầu như luôn filter theo một column cụ thể. Ví dụ created_at, tenant_id, region. Nếu pattern query đa dạng — lúc filter theo date, lúc theo customer, lúc theo product — thì partition theo column nào cũng không tối ưu cho tất cả.
Cần xóa data cũ thường xuyên. DELETE FROM orders WHERE created_at < '2023-01-01' trên bảng 500 triệu row sẽ tạo ra lượng dead tuple khổng lồ, VACUUM chạy mệt nghỉ. Nhưng DROP TABLE orders_2022 thì xong trong millisecond.
VACUUM và maintenance đang là bottleneck. Khi bảng quá lớn, autovacuum chạy lâu, tốn I/O, ảnh hưởng đến query khác. Partition nhỏ hơn → vacuum nhanh hơn.
Và ngược lại, ĐỪNG partition khi:
- Bảng chỉ vài triệu row — index là đủ
- Query không có filter phù hợp để partition pruning hoạt động
- Bạn chưa tối ưu index, query plan, hay connection pooling — partition không phải phép màu thay thế tuning cơ bản
- Team chưa quen với PostgreSQL partitioning — complexity cao, debug khó hơn
Ba kiểu partition
Range Partition
Phổ biến nhất. Chia data theo khoảng giá trị — thường là thời gian.
CREATE TABLE orders (
id BIGINT GENERATED ALWAYS AS IDENTITY,
customer_id BIGINT NOT NULL,
total NUMERIC(12,2) NOT NULL,
status VARCHAR(20) NOT NULL,
created_at TIMESTAMPTZ NOT NULL,
PRIMARY KEY (id, created_at) -- partition key PHẢI nằm trong PK
) PARTITION BY RANGE (created_at);
Tạo partition cho từng năm:
CREATE TABLE orders_2024 PARTITION OF orders
FOR VALUES FROM ('2024-01-01') TO ('2025-01-01');
CREATE TABLE orders_2025 PARTITION OF orders
FOR VALUES FROM ('2025-01-01') TO ('2026-01-01');
CREATE TABLE orders_2026 PARTITION OF orders
FOR VALUES FROM ('2026-01-01') TO ('2027-01-01');
-- default partition bắt mọi thứ không thuộc range nào
CREATE TABLE orders_default PARTITION OF orders DEFAULT;
Lưu ý quan trọng: range là [inclusive, exclusive) — FROM ('2025-01-01') TO ('2026-01-01') bao gồm 2025-01-01 00:00:00 nhưng KHÔNG bao gồm 2026-01-01 00:00:00. Đây là lỗi phổ biến nhất khi setup range partition.
List Partition
Chia theo giá trị cụ thể — phù hợp cho multi-tenant, chia theo region, theo status.
CREATE TABLE events (
id BIGINT GENERATED ALWAYS AS IDENTITY,
tenant_id INT NOT NULL,
event_type VARCHAR(50) NOT NULL,
payload JSONB,
created_at TIMESTAMPTZ NOT NULL,
PRIMARY KEY (id, tenant_id)
) PARTITION BY LIST (tenant_id);
CREATE TABLE events_tenant_1 PARTITION OF events
FOR VALUES IN (1);
CREATE TABLE events_tenant_2 PARTITION OF events
FOR VALUES IN (2);
CREATE TABLE events_tenant_3 PARTITION OF events
FOR VALUES IN (3, 4, 5); -- gộp tenant nhỏ vào chung
CREATE TABLE events_default PARTITION OF events DEFAULT;
Ưu điểm: query WHERE tenant_id = 2 chỉ scan đúng partition của tenant 2. Rất mạnh cho SaaS multi-tenant — mỗi tenant một partition, data isolation tự nhiên.
Nhược điểm: nếu có 1.000 tenant thì 1.000 partition — quản lý mệt. Giải pháp là gộp những tenant nhỏ vào chung partition.
Hash Partition
Chia đều data dựa trên hash value. Dùng khi không có range hay list tự nhiên, chỉ cần distribute data đều.
CREATE TABLE sessions (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
user_id BIGINT NOT NULL,
data JSONB,
expires_at TIMESTAMPTZ
) PARTITION BY HASH (id);
CREATE TABLE sessions_p0 PARTITION OF sessions
FOR VALUES WITH (MODULUS 4, REMAINDER 0);
CREATE TABLE sessions_p1 PARTITION OF sessions
FOR VALUES WITH (MODULUS 4, REMAINDER 1);
CREATE TABLE sessions_p2 PARTITION OF sessions
FOR VALUES WITH (MODULUS 4, REMAINDER 2);
CREATE TABLE sessions_p3 PARTITION OF sessions
FOR VALUES WITH (MODULUS 4, REMAINDER 3);
4 partition, data phân bổ đều dựa trên hash của id. Mỗi partition chứa khoảng 25% data.
Thực tế mình ít dùng hash partition vì nó không hỗ trợ pruning tốt cho range query. Bạn không thể nói "lấy sessions trong tháng này" và expect PostgreSQL chỉ scan 1 partition — nó sẽ scan tất cả. Hash partition chỉ thực sự hữu ích khi bạn luôn query bằng exact match trên partition key.
Triển khai thực tế: partition bảng orders 200 triệu row
Đây là phần khó nhất — partition một bảng đang chạy production, có data, có traffic. Không thể DROP TABLE rồi tạo lại.
Bước 1: Tạo bảng mới đã partition
-- tạo bảng mới với partitioning
CREATE TABLE orders_partitioned (
id BIGINT GENERATED ALWAYS AS IDENTITY,
customer_id BIGINT NOT NULL,
total NUMERIC(12,2) NOT NULL,
status VARCHAR(20) NOT NULL,
created_at TIMESTAMPTZ NOT NULL,
PRIMARY KEY (id, created_at)
) PARTITION BY RANGE (created_at);
-- tạo partitions
CREATE TABLE orders_part_2024 PARTITION OF orders_partitioned
FOR VALUES FROM ('2024-01-01') TO ('2025-01-01');
CREATE TABLE orders_part_2025 PARTITION OF orders_partitioned
FOR VALUES FROM ('2025-01-01') TO ('2026-01-01');
CREATE TABLE orders_part_2026 PARTITION OF orders_partitioned
FOR VALUES FROM ('2026-01-01') TO ('2027-01-01');
CREATE TABLE orders_part_default PARTITION OF orders_partitioned DEFAULT;
-- tạo index trên từng partition
CREATE INDEX idx_orders_2024_customer ON orders_part_2024 (customer_id);
CREATE INDEX idx_orders_2024_status ON orders_part_2024 (status);
-- lặp lại cho từng partition...
Bước 2: Migrate data
Không dùng INSERT INTO ... SELECT * FROM một phát — với 200 triệu row, nó sẽ lock bảng cũ rất lâu và tốn WAL khổng lồ. Migrate theo batch:
-- migrate từng batch 50.000 row
DO $$
DECLARE
batch_size INT := 50000;
last_id BIGINT := 0;
rows_moved INT;
BEGIN
LOOP
INSERT INTO orders_partitioned (customer_id, total, status, created_at)
SELECT customer_id, total, status, created_at
FROM orders_old
WHERE id > last_id
ORDER BY id
LIMIT batch_size;
GET DIAGNOSTICS rows_moved = ROW_COUNT;
EXIT WHEN rows_moved = 0;
-- cập nhật last_id cho batch tiếp theo
SELECT MAX(id) INTO last_id
FROM orders_old
WHERE id > last_id - batch_size + 1
LIMIT 1;
-- cho vacuum có cơ hội chạy
PERFORM pg_sleep(0.1);
RAISE NOTICE 'Migrated % rows, last_id: %', rows_moved, last_id;
END LOOP;
END $$;
Bước 3: Cutover
Khi data đã sync xong (có thể dùng logical replication cho zero-downtime), swap tên bảng:
BEGIN;
-- đổi tên trong một transaction
ALTER TABLE orders RENAME TO orders_old_backup;
ALTER TABLE orders_partitioned RENAME TO orders;
-- cập nhật sequence nếu cần
SELECT setval('orders_id_seq', (SELECT MAX(id) FROM orders));
COMMIT;
Application code không cần thay đổi gì — tên bảng vẫn là orders.
Bước 4: Verify
-- kiểm tra partition pruning hoạt động
EXPLAIN (ANALYZE, BUFFERS)
SELECT * FROM orders
WHERE created_at BETWEEN '2025-06-01' AND '2025-06-30';
-- output nên chỉ có Seq Scan hoặc Index Scan trên orders_part_2025
-- KHÔNG scan các partition khác
Nếu output vẫn scan tất cả partition, kiểm tra enable_partition_pruning:
SHOW enable_partition_pruning; -- phải là 'on'
SET enable_partition_pruning = on; -- nếu bị tắt
Tự động tạo partition mới
Bạn không muốn mỗi đầu năm phải SSH vào server chạy CREATE TABLE bằng tay. Tạo cron job hoặc function tự động:
CREATE OR REPLACE FUNCTION create_monthly_partition()
RETURNS void AS $$
DECLARE
partition_date DATE;
partition_name TEXT;
start_date DATE;
end_date DATE;
BEGIN
-- tạo partition cho tháng tiếp theo
partition_date := DATE_TRUNC('month', NOW()) + INTERVAL '1 month';
partition_name := 'orders_' || TO_CHAR(partition_date, 'YYYY_MM');
start_date := partition_date;
end_date := partition_date + INTERVAL '1 month';
-- kiểm tra đã tồn tại chưa
IF NOT EXISTS (
SELECT 1 FROM pg_tables
WHERE tablename = partition_name
) THEN
EXECUTE FORMAT(
'CREATE TABLE %I PARTITION OF orders
FOR VALUES FROM (%L) TO (%L)',
partition_name, start_date, end_date
);
-- tạo index
EXECUTE FORMAT(
'CREATE INDEX %I ON %I (customer_id)',
'idx_' || partition_name || '_customer',
partition_name
);
RAISE NOTICE 'Created partition: %', partition_name;
END IF;
END;
$$ LANGUAGE plpgsql;
Lên lịch chạy hàng tuần bằng pg_cron:
-- cài pg_cron extension
CREATE EXTENSION IF NOT EXISTS pg_cron;
-- chạy mỗi chủ nhật lúc 3h sáng
SELECT cron.schedule('create-partition', '0 3 * * 0',
'SELECT create_monthly_partition()');
Tại sao chạy hàng tuần mà không phải hàng tháng? Vì nếu cron miss một lần (server restart, maintenance window), bạn vẫn có backup run. Hàm đã check IF NOT EXISTS nên chạy nhiều lần cũng không sao.
Index trên bảng partition
Đây là phần hay gây confusion. Khi bạn tạo index trên parent table, PostgreSQL tự tạo index tương ứng trên từng partition:
-- tạo trên parent → tự tạo trên tất cả partition
CREATE INDEX idx_orders_customer ON orders (customer_id);
Nhưng nếu bạn cần index khác nhau cho từng partition — ví dụ partition cũ không cần index vì ít query — thì tạo trực tiếp trên partition con:
-- chỉ index partition hiện tại
CREATE INDEX idx_orders_2026_status ON orders_part_2026 (status)
WHERE status IN ('pending', 'processing');
Partial index trên partition cụ thể — cực kỳ hiệu quả cho hot partition.
Xóa data cũ
Đây là lợi ích lớn nhất của partitioning mà nhiều người không nhận ra cho đến khi cần:
-- CÁCH CŨ: xóa 100 triệu row, lock bảng, VACUUM chạy 2 tiếng
DELETE FROM orders WHERE created_at < '2023-01-01';
-- CÁCH MỚI: drop partition, xong trong millisecond
ALTER TABLE orders DETACH PARTITION orders_part_2022;
DROP TABLE orders_part_2022;
DETACH PARTITION tách partition ra khỏi parent table — query mới không thấy data nữa. Sau đó DROP TABLE xóa hẳn. Không dead tuple, không VACUUM, không bloat. Nhanh gọn.
Từ PostgreSQL 14 trở đi, bạn có thể dùng DETACH PARTITION ... CONCURRENTLY để không block query đang chạy.
Những bài học đau thương
Partition key phải nằm trong PRIMARY KEY. Đây là constraint của PostgreSQL — không thể có unique constraint trên column mà không bao gồm partition key. Nghĩa là PRIMARY KEY (id) sẽ fail, phải là PRIMARY KEY (id, created_at). Nếu application rely on id unique toàn bảng, bạn cần thêm logic kiểm tra.
Foreign key references. Từ PostgreSQL 12, bạn có thể tạo foreign key TỪ partitioned table đến bảng khác. Nhưng foreign key TỚI partitioned table (bảng khác reference sang partition) thì hạn chế hơn. Kiểm tra kỹ trước khi migrate.
Join performance. Nếu bạn JOIN hai bảng đều partitioned, PostgreSQL có thể tận dụng partition-wise join — join từng cặp partition tương ứng thay vì hash join toàn bộ. Nhưng feature này mặc định TẮT:
SET enable_partitionwise_join = on;
SET enable_partitionwise_aggregate = on;
Test kỹ trước khi bật trên production — nó có thể tạo ra quá nhiều sub-plan với bảng có nhiều partition.
Quá nhiều partition. Mỗi partition là một bảng vật lý với metadata riêng. 10.000 partition = 10.000 bảng. Query planning sẽ chậm vì planner phải evaluate từng partition. Mình khuyên giữ dưới 200-300 partition. Nếu partition theo tháng, 300 partition = 25 năm data — thừa cho hầu hết use case.
DEFAULT partition phình to. Nếu bạn quên tạo partition cho tháng mới, data sẽ rơi vào default partition. Khi default partition lớn, mọi query không match partition nào cũng sẽ scan default. Luôn monitor size của default partition — nó nên gần bằng 0.
Monitoring
Một số query hữu ích để theo dõi partition:
-- kiểm tra kích thước từng partition
SELECT
schemaname || '.' || tablename AS partition,
pg_size_pretty(pg_total_relation_size(schemaname || '.' || tablename)) AS total_size,
pg_size_pretty(pg_relation_size(schemaname || '.' || tablename)) AS data_size,
n_live_tup AS estimated_rows
FROM pg_stat_user_tables
WHERE tablename LIKE 'orders_%'
ORDER BY pg_total_relation_size(schemaname || '.' || tablename) DESC;
-- kiểm tra partition pruning có hoạt động không
EXPLAIN (COSTS OFF)
SELECT * FROM orders WHERE created_at = '2025-06-15';
-- output nên chỉ show scan trên orders_part_2025
-- kiểm tra default partition có data không
SELECT COUNT(*) FROM orders_default;
-- kết quả nên là 0 hoặc rất nhỏ
Tổng kết
Partitioning không phải phép thuật — nó là trade-off. Bạn đánh đổi sự đơn giản (một bảng duy nhất) lấy performance (query nhanh hơn, maintenance dễ hơn, xóa data tức thì). Trade-off này chỉ đáng khi bảng thực sự lớn và query pattern phù hợp.
Ba nguyên tắc mình luôn theo: thứ nhất, tối ưu index trước, partition sau — nhiều bảng hàng chục triệu row chạy tốt chỉ với index đúng. Thứ hai, chọn partition key dựa trên query pattern thực tế, không phải lý thuyết — xem slow query log, xem application code filter theo cái gì nhiều nhất. Thứ ba, luôn có default partition và monitor nó — đó là hệ thống cảnh báo sớm tốt nhất khi bạn quên tạo partition mới.
PostgreSQL partitioning đã mature rất nhiều từ phiên bản 10 đến 16. Declarative syntax dễ dùng, partition pruning thông minh, và tooling ngày càng tốt. Nếu bảng của bạn đang chạm ngưỡng mà index không cứu được nữa, đây là bước tiếp theo hợp lý.

Leave a comment
Your email address will not be published. Required fields are marked *