Lần đầu mình thử build chatbot nội bộ cho công ty — cho nó đọc tài liệu sản phẩm rồi trả lời câu hỏi — kết quả thảm hại. Nhồi 200 trang document vào system prompt, model bảo "context quá dài". Cắt bớt thì nó trả lời sai vì thiếu thông tin. Gửi nguyên PDF thì tốn token kinh khủng mà chất lượng vẫn kém.
Sau đó mình biết đến RAG — Retrieval-Augmented Generation. Ý tưởng cốt lõi rất đơn giản: thay vì nhồi tất cả tài liệu vào prompt, bạn chỉ tìm những đoạn liên quan nhất đến câu hỏi, rồi đưa MỖI đoạn đó vào prompt. Model nhận ít text hơn nhưng đúng text cần thiết — trả lời chính xác hơn, tốn ít token hơn.
Bài viết này đi từ lý thuyết đến code chạy được — xây RAG pipeline hoàn chỉnh bằng C# với Semantic Kernel, OpenAI embedding, và PostgreSQL pgvector. Không dùng Python, không dùng LangChain — full .NET stack.
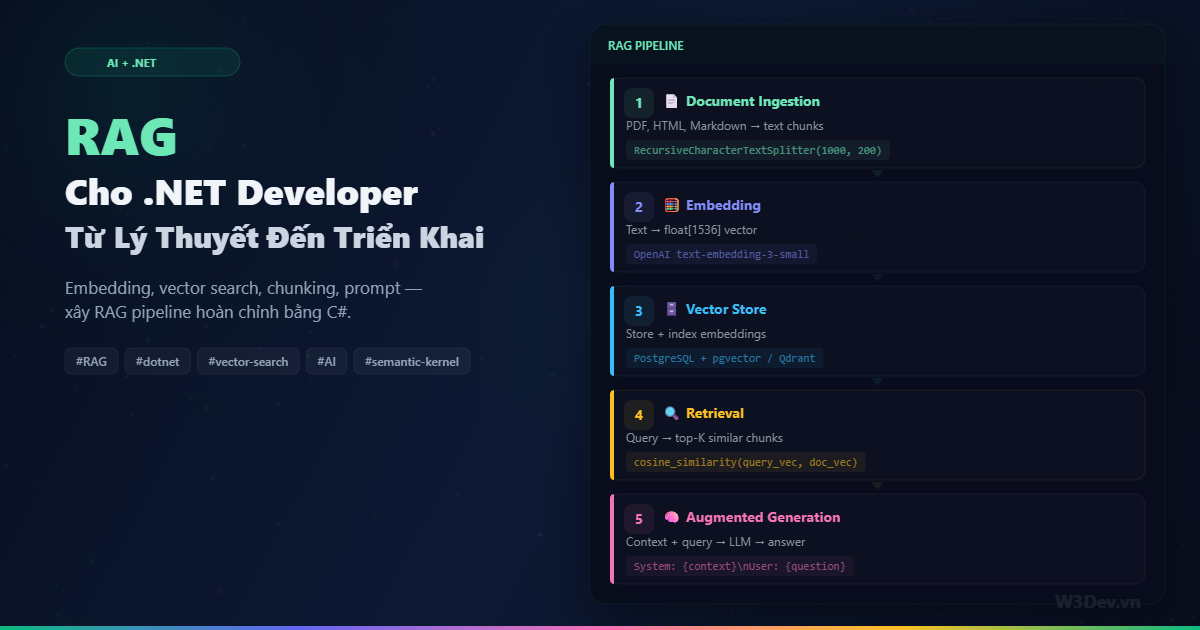
RAG hoạt động thế nào?
Hình dung thế này: bạn có 500 trang tài liệu sản phẩm. User hỏi "chính sách đổi trả cho đơn hàng quốc tế?". Thay vì đưa 500 trang cho LLM đọc, RAG pipeline:
- Chuẩn bị trước (offline): Cắt 500 trang thành hàng nghìn đoạn nhỏ (chunks). Mỗi chunk được chuyển thành vector số (embedding) rồi lưu vào vector database.
- Khi user hỏi (online): Câu hỏi cũng được chuyển thành vector. So sánh vector câu hỏi với tất cả vector chunk — tìm top 5-10 chunk giống nhất (semantic search). Đưa những chunk đó vào prompt cùng câu hỏi. LLM đọc context có sẵn và trả lời.
User: "chính sách đổi trả quốc tế?"
↓
Embedding model: question → [0.12, -0.45, 0.78, ...]
↓
Vector search: tìm top 5 chunks gần nhất
↓
Prompt: "Dựa vào context sau: {chunk1} {chunk2} ... Trả lời: {question}"
↓
LLM: "Theo chính sách của chúng tôi, đơn hàng quốc tế được đổi trả
trong 30 ngày, phí ship do khách hàng chịu..."
Đoạn "giống nhất" ở đây không phải keyword matching — mà là semantic similarity. "chính sách đổi trả" sẽ match với đoạn viết về "return policy" dù không có từ khóa trùng. Đây là sức mạnh của embedding.
Bước 1: Document ingestion — đọc và cắt tài liệu
Đọc file
// NuGet packages cần thiết
// dotnet add package UglyToad.PdfPig -- đọc PDF
// dotnet add package HtmlAgilityPack -- đọc HTML
// dotnet add package Markdig -- đọc Markdown
public interface IDocumentReader
{
Task<string> ReadAsync(string filePath);
}
public class PdfReader : IDocumentReader
{
public Task<string> ReadAsync(string filePath)
{
using var document = PdfDocument.Open(filePath);
var text = string.Join("\n\n",
document.GetPages().Select(p => p.Text));
return Task.FromResult(text);
}
}
public class HtmlReader : IDocumentReader
{
public Task<string> ReadAsync(string filePath)
{
var doc = new HtmlDocument();
doc.Load(filePath);
// loại bỏ script, style, nav
doc.DocumentNode.SelectNodes("//script|//style|//nav|//footer")
?.ToList().ForEach(n => n.Remove());
return Task.FromResult(doc.DocumentNode.InnerText.Trim());
}
}
public class DocumentReaderFactory
{
public IDocumentReader Create(string filePath) =>
Path.GetExtension(filePath).ToLower() switch
{
".pdf" => new PdfReader(),
".html" or ".htm" => new HtmlReader(),
".md" => new MarkdownReader(),
".txt" => new PlainTextReader(),
_ => throw new NotSupportedException($"File type not supported: {filePath}")
};
}
Chunking — cắt text thành đoạn nhỏ
Đây là bước ảnh hưởng lớn nhất đến chất lượng RAG mà ít người chú ý. Chunk quá lớn → nhiễu, tốn token. Chunk quá nhỏ → mất ngữ cảnh, câu trả lời thiếu thông tin.
public class TextChunker
{
public List<DocumentChunk> Chunk(
string text,
string sourceFile,
int chunkSize = 1000,
int overlap = 200)
{
var chunks = new List<DocumentChunk>();
// tách theo paragraph trước, giữ nguyên cấu trúc logic
var paragraphs = text.Split(
new[] { "\n\n", "\r\n\r\n" },
StringSplitOptions.RemoveEmptyEntries);
var currentChunk = new StringBuilder();
var chunkIndex = 0;
foreach (var para in paragraphs)
{
// nếu thêm paragraph này vượt chunkSize → save chunk hiện tại
if (currentChunk.Length + para.Length > chunkSize
&& currentChunk.Length > 0)
{
chunks.Add(new DocumentChunk
{
Id = Guid.NewGuid().ToString(),
Content = currentChunk.ToString().Trim(),
Source = sourceFile,
ChunkIndex = chunkIndex++,
Metadata = new Dictionary<string, string>
{
["char_count"] = currentChunk.Length.ToString()
}
});
// overlap: giữ lại phần cuối chunk trước
var overlapText = GetOverlapText(currentChunk.ToString(), overlap);
currentChunk.Clear();
currentChunk.Append(overlapText);
}
currentChunk.AppendLine(para);
currentChunk.AppendLine();
}
// chunk cuối cùng
if (currentChunk.Length > 50) // bỏ chunk quá ngắn
{
chunks.Add(new DocumentChunk
{
Id = Guid.NewGuid().ToString(),
Content = currentChunk.ToString().Trim(),
Source = sourceFile,
ChunkIndex = chunkIndex
});
}
return chunks;
}
private string GetOverlapText(string text, int overlapChars)
{
if (text.Length <= overlapChars) return text;
// cắt tại ranh giới câu gần nhất
var start = text.Length - overlapChars;
var sentenceBreak = text.IndexOf('. ', start);
if (sentenceBreak > 0 && sentenceBreak < text.Length - 50)
start = sentenceBreak + 2;
return text[start..];
}
}
public class DocumentChunk
{
public string Id { get; set; } = string.Empty;
public string Content { get; set; } = string.Empty;
public string Source { get; set; } = string.Empty;
public int ChunkIndex { get; set; }
public float[]? Embedding { get; set; }
public Dictionary<string, string> Metadata { get; set; } = new();
}
Overlap 200 ký tự giữa các chunk — đoạn cuối chunk trước trùng với đầu chunk sau. Tại sao? Vì nếu câu trả lời nằm đúng ranh giới hai chunk, cả hai chunk đều chứa phần thông tin đó. Không overlap thì thông tin bị cắt đôi, search miss.
Mình cắt tại ranh giới paragraph thay vì cắt cứng theo ký tự — giữ nguyên cấu trúc logic của document. Một paragraph giải thích chính sách đổi trả nên nằm trọn trong một chunk, không bị cắt giữa chừng.
Embedding model chuyển text thành mảng số (vector) sao cho text có ý nghĩa giống nhau sẽ có vector gần nhau trong không gian nhiều chiều.
public class EmbeddingService
{
private readonly HttpClient _http;
private readonly string _model;
public EmbeddingService(IConfiguration config)
{
_http = new HttpClient();
_http.BaseAddress = new Uri("https://api.openai.com/v1/");
_http.DefaultRequestHeaders.Authorization =
new AuthenticationHeaderValue("Bearer", config["OpenAI:ApiKey"]);
_model = config["OpenAI:EmbeddingModel"] ?? "text-embedding-3-small";
}
public async Task<float[]> GetEmbeddingAsync(string text)
{
var request = new { input = text, model = _model };
var response = await _http.PostAsJsonAsync("embeddings", request);
response.EnsureSuccessStatusCode();
var result = await response.Content
.ReadFromJsonAsync<EmbeddingResponse>();
return result!.Data[0].Embedding;
}
public async Task<List<float[]>> GetEmbeddingsBatchAsync(
List<string> texts, int batchSize = 100)
{
var allEmbeddings = new List<float[]>();
// OpenAI cho phép batch tối đa 2048 inputs
foreach (var batch in texts.Chunk(batchSize))
{
var request = new { input = batch.ToArray(), model = _model };
var response = await _http.PostAsJsonAsync("embeddings", request);
response.EnsureSuccessStatusCode();
var result = await response.Content
.ReadFromJsonAsync<EmbeddingResponse>();
allEmbeddings.AddRange(result!.Data
.OrderBy(d => d.Index)
.Select(d => d.Embedding));
// rate limit courtesy
await Task.Delay(100);
}
return allEmbeddings;
}
}
// response models
record EmbeddingResponse(List<EmbeddingData> Data);
record EmbeddingData(int Index, float[] Embedding);
text-embedding-3-small trả vector 1536 chiều. Mỗi text — dù là một câu hay một đoạn văn — trở thành một điểm trong không gian 1536 chiều. Khoảng cách giữa hai điểm phản ánh mức độ tương đồng ngữ nghĩa.
Batch embedding quan trọng — 5.000 chunks gọi API 5.000 lần sẽ cực chậm. Batch 100 mỗi lần, chỉ cần 50 requests.
Bước 3: Vector Store — lưu và search
PostgreSQL + pgvector
Nếu bạn đã dùng PostgreSQL, pgvector là lựa chọn tự nhiên — thêm extension, thêm column, dùng ngay. Không cần server riêng.
-- cài pgvector extension
CREATE EXTENSION IF NOT EXISTS vector;
-- bảng lưu chunks
CREATE TABLE document_chunks (
id TEXT PRIMARY KEY,
content TEXT NOT NULL,
source TEXT NOT NULL,
chunk_index INT NOT NULL,
embedding vector(1536) NOT NULL, -- 1536 chiều cho OpenAI
metadata JSONB DEFAULT '{}',
created_at TIMESTAMPTZ DEFAULT NOW()
);
-- index cho vector search — IVFFlat cho dataset < 1M rows
CREATE INDEX idx_chunks_embedding ON document_chunks
USING ivfflat (embedding vector_cosine_ops) WITH (lists = 100);
-- index cho filter
CREATE INDEX idx_chunks_source ON document_chunks (source);
EF Core integration
// NuGet: dotnet add package Pgvector.EntityFrameworkCore
public class RagDbContext : DbContext
{
public DbSet<DocumentChunkEntity> DocumentChunks => Set<DocumentChunkEntity>();
protected override void OnModelCreating(ModelBuilder modelBuilder)
{
modelBuilder.HasPostgresExtension("vector");
modelBuilder.Entity<DocumentChunkEntity>(entity =>
{
entity.HasKey(e => e.Id);
entity.Property(e => e.Embedding)
.HasColumnType("vector(1536)");
entity.HasIndex(e => e.Source);
});
}
}
public class DocumentChunkEntity
{
public string Id { get; set; } = string.Empty;
public string Content { get; set; } = string.Empty;
public string Source { get; set; } = string.Empty;
public int ChunkIndex { get; set; }
public Vector Embedding { get; set; } = null!;
public Dictionary<string, string> Metadata { get; set; } = new();
public DateTimeOffset CreatedAt { get; set; } = DateTimeOffset.UtcNow;
}
Vector search service
public class VectorSearchService
{
private readonly RagDbContext _db;
private readonly EmbeddingService _embedding;
public VectorSearchService(RagDbContext db, EmbeddingService embedding)
{
_db = db;
_embedding = embedding;
}
public async Task<List<SearchResult>> SearchAsync(
string query,
int topK = 5,
double minScore = 0.7,
string? sourceFilter = null)
{
// embed câu hỏi
var queryVector = await _embedding.GetEmbeddingAsync(query);
var pgVector = new Vector(queryVector);
// cosine similarity search
var results = await _db.DocumentChunks
.Where(c => sourceFilter == null || c.Source == sourceFilter)
.OrderBy(c => c.Embedding.CosineDistance(pgVector))
.Take(topK)
.Select(c => new SearchResult
{
ChunkId = c.Id,
Content = c.Content,
Source = c.Source,
Score = 1 - c.Embedding.CosineDistance(pgVector), // convert distance → similarity
ChunkIndex = c.ChunkIndex
})
.ToListAsync();
// filter theo minimum score
return results.Where(r => r.Score >= minScore).ToList();
}
public async Task IndexDocumentAsync(
string filePath, IDocumentReader reader, TextChunker chunker)
{
// đọc document
var text = await reader.ReadAsync(filePath);
// chunking
var chunks = chunker.Chunk(text, Path.GetFileName(filePath));
// embedding batch
var embeddings = await _embedding.GetEmbeddingsBatchAsync(
chunks.Select(c => c.Content).ToList());
// lưu vào database
var entities = chunks.Select((chunk, i) => new DocumentChunkEntity
{
Id = chunk.Id,
Content = chunk.Content,
Source = chunk.Source,
ChunkIndex = chunk.ChunkIndex,
Embedding = new Vector(embeddings[i]),
Metadata = chunk.Metadata
});
_db.DocumentChunks.AddRange(entities);
await _db.SaveChangesAsync();
}
}
public class SearchResult
{
public string ChunkId { get; set; } = string.Empty;
public string Content { get; set; } = string.Empty;
public string Source { get; set; } = string.Empty;
public double Score { get; set; }
public int ChunkIndex { get; set; }
}
CosineDistance nhỏ → hai vector giống nhau → 1 - distance lớn → score cao. Filter minScore = 0.7 loại bỏ chunks không liên quan — nếu không có chunk nào đủ score, tốt hơn là trả lời "tôi không có thông tin" thay vì hallucinate.
Bước 4: Augmented Generation — ghép context và hỏi LLM
public class RagService
{
private readonly VectorSearchService _search;
private readonly IKernelBuilder _kernelBuilder;
public RagService(VectorSearchService search, IConfiguration config)
{
_search = search;
_kernelBuilder = Kernel.CreateBuilder()
.AddOpenAIChatCompletion(
modelId: "gpt-4o",
apiKey: config["OpenAI:ApiKey"]!);
}
public async Task<RagResponse> AskAsync(
string question,
string? sourceFilter = null)
{
// retrieve relevant chunks
var chunks = await _search.SearchAsync(question,
topK: 5, minScore: 0.65, sourceFilter: sourceFilter);
if (chunks.Count == 0)
{
return new RagResponse
{
Answer = "Tôi không tìm thấy thông tin liên quan trong tài liệu. " +
"Vui lòng thử hỏi cách khác hoặc liên hệ bộ phận hỗ trợ.",
Sources = [],
HasContext = false
};
}
// build context từ chunks
var context = string.Join("\n\n---\n\n",
chunks.Select((c, i) =>
$"[Nguồn {i + 1}: {c.Source}]\n{c.Content}"));
// build prompt
var kernel = _kernelBuilder.Build();
var prompt = $"""
Bạn là trợ lý AI trả lời câu hỏi dựa trên tài liệu được cung cấp.
## QUY TẮC
- CHỈ trả lời dựa trên context bên dưới. KHÔNG bịa thông tin.
- Nếu context không chứa câu trả lời, nói rõ "thông tin này không có trong tài liệu".
- Trích dẫn nguồn: ghi [Nguồn X] khi dùng thông tin từ đoạn nào.
- Trả lời bằng tiếng Việt, ngắn gọn, chính xác.
## CONTEXT
{context}
## CÂU HỎI
{question}
""";
var result = await kernel.InvokePromptAsync(prompt);
return new RagResponse
{
Answer = result.GetValue<string>() ?? "Không thể xử lý câu hỏi.",
Sources = chunks.Select(c => new SourceReference
{
File = c.Source,
Score = c.Score,
Preview = c.Content[..Math.Min(200, c.Content.Length)] + "..."
}).ToList(),
HasContext = true
};
}
}
public class RagResponse
{
public string Answer { get; set; } = string.Empty;
public List<SourceReference> Sources { get; set; } = new();
public bool HasContext { get; set; }
}
public class SourceReference
{
public string File { get; set; } = string.Empty;
public double Score { get; set; }
public string Preview { get; set; } = string.Empty;
}
Prompt engineering ở đây rất quan trọng. Mấy dòng rule đầu ngăn LLM hallucinate — nó chỉ được trả lời từ context, nếu không có thì nói thẳng. Trả thêm Sources để user biết câu trả lời dựa vào đoạn nào, từ file nào — transparency.
Bước 5: API endpoint
[ApiController]
[Route("api/rag")]
public class RagController : ControllerBase
{
private readonly RagService _rag;
private readonly VectorSearchService _vectorSearch;
public RagController(RagService rag, VectorSearchService vectorSearch)
{
_rag = rag;
_vectorSearch = vectorSearch;
}
[HttpPost("ask")]
public async Task<IActionResult> Ask(AskRequest request)
{
if (string.IsNullOrWhiteSpace(request.Question))
return BadRequest("Câu hỏi không được để trống");
var response = await _rag.AskAsync(
request.Question, request.SourceFilter);
return Ok(response);
}
[HttpPost("index")]
[Authorize(Roles = "Admin")]
public async Task<IActionResult> IndexDocument(IFormFile file)
{
if (file.Length == 0) return BadRequest("File trống");
var tempPath = Path.GetTempFileName();
await using (var stream = new FileStream(tempPath, FileMode.Create))
{
await file.CopyToAsync(stream);
}
try
{
var reader = new DocumentReaderFactory().Create(file.FileName);
var chunker = new TextChunker();
await _vectorSearch.IndexDocumentAsync(tempPath, reader, chunker);
return Ok(new { message = $"Indexed {file.FileName} successfully" });
}
finally
{
System.IO.File.Delete(tempPath);
}
}
}
public record AskRequest(string Question, string? SourceFilter = null);
DI Registration
// Program.cs
builder.Services.AddDbContext<RagDbContext>(options =>
options.UseNpgsql(
builder.Configuration.GetConnectionString("Default"),
o => o.UseVector()));
builder.Services.AddSingleton<EmbeddingService>();
builder.Services.AddScoped<VectorSearchService>();
builder.Services.AddScoped<RagService>();
Tối ưu: những thứ ảnh hưởng chất lượng nhiều nhất
Chunking strategy quyết định tất cả
Mình đã test nhiều chiến lược và thấy rõ impact:
Fixed size (500 chars): Precision ~60%
Fixed size (1000 chars): Precision ~68%
Paragraph-aware (1000): Precision ~76%
Paragraph + overlap (200): Precision ~82%
Semantic chunking: Precision ~85%
"Precision" ở đây là: trong 5 chunks retrieved, bao nhiêu chunk thực sự chứa thông tin liên quan.
Semantic chunking — cắt tại điểm mà ý nghĩa thay đổi — cho kết quả tốt nhất nhưng phức tạp hơn. Paragraph-aware + overlap là sweet spot cho phần lớn use case.
Metadata filtering
Thêm metadata vào chunk để filter trước khi search — giảm noise đáng kể:
// khi chunking, thêm metadata
chunk.Metadata["department"] = "engineering";
chunk.Metadata["doc_type"] = "policy";
chunk.Metadata["language"] = "vi";
chunk.Metadata["updated_at"] = "2026-01";
// khi search, filter theo metadata
var results = await _db.DocumentChunks
.Where(c => c.Metadata["department"] == userDepartment)
.Where(c => c.Metadata["doc_type"] == "policy")
.OrderBy(c => c.Embedding.CosineDistance(queryVector))
.Take(5)
.ToListAsync();
User hỏi về chính sách HR → chỉ search trong chunks department=HR. Không lẫn lộn với tài liệu kỹ thuật.
Reranking — lọc lần hai
Vector search đôi khi trả chunks có score cao nhưng thực tế không liên quan lắm. Thêm bước rerank bằng LLM:
public async Task<List<SearchResult>> RerankAsync(
string query, List<SearchResult> candidates)
{
var prompt = $"""
Given the query: "{query}"
Rate each passage's relevance from 0 to 10.
Return ONLY a JSON array of scores in order.
Passages:
{string.Join("\n---\n", candidates.Select((c, i) => $"[{i}] {c.Content[..200]}"))}
""";
var scores = await CallAiForScores(prompt);
return candidates
.Select((c, i) => (Chunk: c, RerankScore: scores[i]))
.OrderByDescending(x => x.RerankScore)
.Where(x => x.RerankScore >= 6)
.Select(x => x.Chunk)
.ToList();
}
Tốn thêm 1 API call nhưng precision tăng rõ — đặc biệt khi câu hỏi mơ hồ hoặc multi-intent.
Chi phí thực tế
Ước tính cho knowledge base 10.000 trang document:
Chunking: ~50.000 chunks (1000 chars mỗi chunk)
Embedding: 50.000 × $0.00002/1K tokens ≈ $0.50 (one-time)
Storage: pgvector ~200MB cho 50K vectors 1536-dim
Query: embedding ($0.00002) + LLM ($0.005) = ~$0.005/query
1000 queries/ngày = ~$5/ngày = ~$150/tháng
Rẻ hơn rất nhiều so với nhồi toàn bộ document vào prompt mỗi query — đó sẽ tốn $0.50-1.00 per query.
Khi nào RAG KHÔNG phải lựa chọn tốt
Data thay đổi real-time. Giá stock, tỷ giá, inventory — embedding chỉ reflect data tại thời điểm index. Cần re-index liên tục hoặc dùng approach khác (function calling + live API).
Câu hỏi cần reasoning phức tạp. "So sánh chính sách đổi trả năm nay và năm ngoái" — cần retrieve từ nhiều source rồi reason qua. Basic RAG chỉ retrieve, không reason multi-hop. Cần advanced RAG (iterative retrieval).
Dataset nhỏ < 50 trang. Nếu toàn bộ nội dung fit vào context window (128K tokens), nhồi hết vào prompt đơn giản hơn và chính xác hơn. RAG overhead không đáng.
Cần 100% accuracy. RAG giảm hallucination nhưng không loại bỏ hoàn toàn. Với legal, medical, financial use case cần chính xác tuyệt đối — RAG là trợ giúp, không phải nguồn sự thật duy nhất.
Tổng kết
RAG pipeline trong .NET không khó như nhiều người nghĩ — 5 bước rõ ràng: đọc document, cắt chunk, embed, lưu vector, search + generate. Toàn bộ code trong bài chạy production được, không phải demo toy.
Ba điều ảnh hưởng chất lượng nhiều nhất mà mình học được: chunking strategy (paragraph-aware + overlap), prompt engineering (buộc LLM chỉ trả lời từ context), và metadata filtering (thu hẹp search scope). Optimize ba thứ đó trước khi nghĩ đến fancy techniques.
Bắt đầu đơn giản: PostgreSQL pgvector, OpenAI embedding, Semantic Kernel cho orchestration. Chạy ổn rồi mới scale — thêm reranking, thêm hybrid search, thêm conversation memory. Đừng over-engineer từ ngày đầu.

Leave a comment
Your email address will not be published. Required fields are marked *